CodeCanyon Crawlomatic - Плагин WordPress
Многофункциональный плагин для WordPress с упором на генерацию постов, известный своей гибкостью и эффективностью, предлагает решение для создания и курирования контента на платформе. Автоматизируя процесс скрапинга контента с различных источников, он упрощает процесс публикации, экономя время и усилия пользователей. Благодаря своим обширным возможностям и удобному интерфейсу, этот инструмент упрощает управление несколькими сайтами и обеспечивает беспрепятственный рабочий процесс для создателей контента.

Особенности плагина
Его инновационный подход к генерации контента выделяет его среди традиционных методов, предлагая динамический способ наполнения веб-сайтов актуальными и увлекательными публикациями. Возможность плагина сканировать несколько сайтов и интеллектуально извлекать информацию способствует более эффективному процессу создания контента. Предоставляя настраиваемые опции для выбора и публикации контента, он дает пользователям возможность адаптировать свои публикации в соответствии с конкретными предпочтениями и требованиями.
Расширенные возможности скрапинга инструмента, в сочетании с его интуитивным дизайном, делают его ценным активом для владельцев веб-сайтов, желающих улучшить онлайн-присутствие. Благодаря функциям автоматизации он не только ускоряет процесс создания контента, но и поддерживает последовательность и качество публикаций. Предоставляя возможность планирования публикаций и установки параметров для извлечения контента, он предлагает проактивный подход к управлению контентом веб-сайта и обеспечению регулярных обновлений.
Для пользователей, стремящихся оптимизировать рабочий процесс создания контента и повысить эффективность, этот плагин представляет собой надежное решение с обширным набором функций и плавной интеграцией с WordPress. Его многофункциональные возможности отвечают широкому спектру потребностей в управлении контентом, начиная от агрегации статей и заканчивая курированием мультимедийного контента. С акцентом на настройку и контроль он дает пользователям возможность разработать индивидуализированную стратегию контента, соответствующую их уникальным целям и задачам.
В заключение, CodeCanyon Crawlomatic представляет собой комплексный инструмент для пользователей WordPress, стремящихся упростить процесс создания контента и повысить видимость своего веб-сайта. Автоматизируя различные аспекты генерации и курирования контента, он предлагает практическое решение для управления несколькими сайтами и обеспечения стабильного потока увлекательных публикаций. Его ориентированный на пользователя дизайн и мощные функции делают его ценным дополнением к арсеналу любого создателя контента, позволяя им сосредоточиться на производстве качественного контента, пока плагин берет на себя остальные задачи.
Спецификации:
| Дата выхода: | 12-07-2019 | |
| Дата обновления: | 20-05-2026 | |
| Тип расширения: | Платный | |
| Лицензия: | GPL | |
| Тематика: | Прочее | |
| Совместимость: | W5.x W6.x | |
| Включает в себя: | Плагин | |
| Языковые пакеты: |
|
|
| Разработчик: | CodeCanyon | |
| Рейтинг: | ||
Скачивание по подписке!
Вам необходимо авторизоваться на сайте и приобрести клубную подписку!
Поделись с друзьями!
Руководство по настройке и безопасному использованию CodeCanyon Crawlomatic
CodeCanyon Crawlomatic - это WordPress-плагин для управляемого crawling и scraping, который превращает найденные на внешнем сайте URL в записи, страницы, товары или другой выбранный тип материалов. В этом руководстве мы не будем пересказывать карточку товара. Вместо этого разберём, как подойти к плагину как к рабочему инструменту: что проверить до установки, какие правила создать первыми, как выбрать селекторы, как не получить поток мусорных публикаций и как понять, что правило действительно работает.
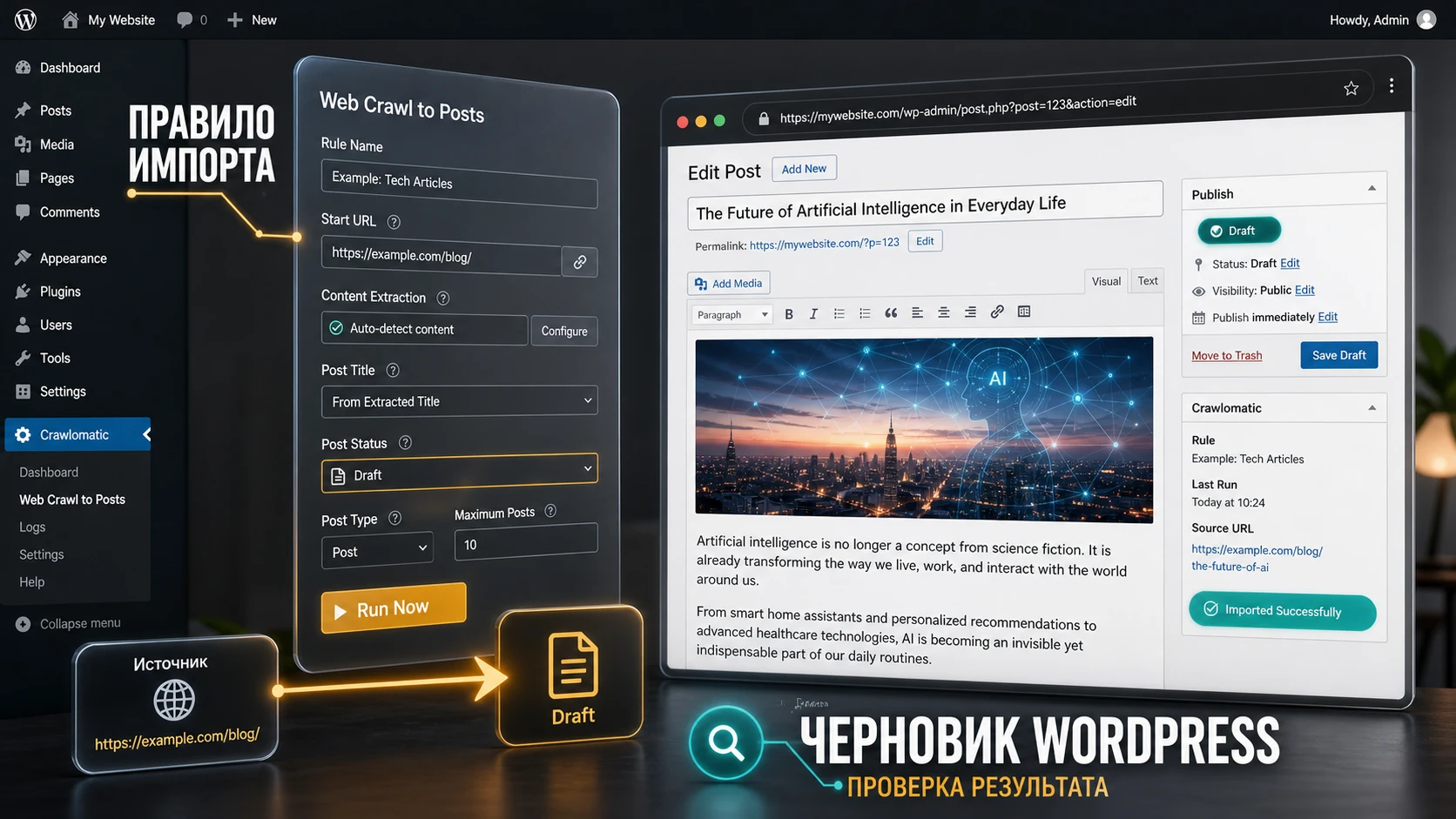
Главная мысль: Crawlomatic полезен только тогда, когда у вас есть понятный источник, разрешённая модель использования контента, ограниченный набор страниц и критерии качества. Если включить его как "автоматическую фабрику постов" без ограничений, он быстро создаст дубли, слишком короткие записи, битые изображения, лишние ссылки и проблемы с правами на материалы. Поэтому настройку лучше строить не вокруг количества публикаций, а вокруг цепочки источник - правило - шаблон - проверка - откат.
В статье есть практический сценарий: импортировать подборку материалов из раздела источника в черновики WordPress, очистить контент от лишних блоков, сохранить изображение, добавить категорию, проверить результат и только после этого включать расписание. Отдельно разберём live scraper shortcode [crawlomatic-scraper], диагностику медленной работы, случаи, когда правило не создаёт новые записи, и похожие решения для задач, где Crawlomatic может быть не лучшим выбором.
Важное ограничение: плагин технически умеет забирать данные с веб-страниц, но это не отменяет правил сайта-источника, авторского права, условий использования, robots.txt и здравой нагрузки на чужой сервер. В учебном сценарии ниже подразумевается, что вы работаете с собственным источником, партнёрским сайтом, открытыми данными, тестовой копией или контентом, на использование которого у вас есть понятное основание.
Как Crawlomatic превращает источник в записи WordPress
В обычной публикации WordPress человек сам открывает редактор, вставляет заголовок, текст, изображение, категорию и нажимает Publish. Crawlomatic делает эту цепочку программно. Вы задаёте стартовый адрес, плагин извлекает ссылки с этой страницы, посещает найденные URL, ищет нужные части HTML, собирает из них запись и сохраняет её с выбранным статусом. Поэтому продукт нужно воспринимать не как магическую кнопку, а как конструктор правил импорта.
Правило состоит из нескольких уровней. Первый уровень - где искать ссылки. Второй - какие ссылки брать и насколько глубоко идти по сайту. Третий - что извлекать на каждой найденной странице: заголовок, основной контент, изображение, дату, категории, теги, дополнительные поля. Четвёртый - как сформировать WordPress-запись: какой статус поставить, в какую категорию отправить, какой шаблон контента применить, копировать ли изображения, удалять ли лишние ссылки, добавлять ли canonical, ограничивать ли длину текста.
Такая модель особенно полезна, когда источник повторяемый. Например, у партнёрского сайта есть раздел с анонсами, у старого проекта есть архив страниц, у каталога есть однотипные карточки товаров, у новостного раздела есть стабильная структура заголовка и основного блока. Если структура меняется от страницы к странице, правило приходится делать осторожнее: сначала тестировать селекторы, затем импортировать малую порцию в черновики, и только после проверки расширять объём.
Что реально автоматизируется
Crawlomatic может создавать записи, страницы и custom post types, назначать автора, статус, категории и теги, подтягивать featured image, работать с шаблонами поста и использовать встроенные переменные вроде %%item_title%%, %%item_content%%, %%item_url%% и %%item_img_url%%. В документации также описаны правила для full content query, фильтрации по словам, минимальной и максимальной длине, удаления элементов по ID или class, настройки логов и очистки старых логов.
Отдельная возможность - [crawlomatic-scraper]. Это не массовый импорт записей, а shortcode для вывода найденного фрагмента прямо в записи, странице или виджете. Он поддерживает CSS selector, XPath, regex, кеширование, timeout, выбор формата вывода и обработку ошибки. Такой режим полезен для маленьких обновляемых фрагментов, но он опаснее для скорости страницы, если отключить кеш или поставить слишком длинный timeout.
Что не стоит автоматизировать без редактора
Если источник не ваш, не стоит импортировать полные статьи без разрешения. Если источник загружает данные через тяжёлый JavaScript, потребуются headless-режимы или внешний сервис, а это добавляет задержки, стоимость и точки отказа. Если исходный сайт часто меняет HTML, селектор может внезапно начать забирать меню, блок рекламы или пустой контейнер. Поэтому для рабочей публикации лучше держать статус Draft или Pending, пока вы не убедились, что правило стабильно.
Практическое правило: сначала настройте один источник, одну категорию и малый лимит записей. Если первая партия прошла чисто, расширяйте глубину crawling, расписание и число материалов за запуск.
Кому подойдёт плагин и где он будет лишним
CodeCanyon Crawlomatic лучше всего подходит владельцам сайтов, которые уже понимают структуру источника и хотят снять повторяющуюся ручную работу. Это может быть перенос собственного старого HTML-архива в WordPress, сбор партнёрских анонсов, импорт карточек из открытого каталога с разрешением, подготовка черновиков для редактора или поддержка внутренней базы знаний, где каждая новая страница источника должна превращаться в черновик.
Плагин особенно уместен, если у вас есть однотипные страницы: одинаковый контейнер заголовка, стабильный блок контента, предсказуемое изображение, понятные категории. В таких условиях селектор можно один раз подобрать, затем контролировать результат через логи и малый лимит публикаций. Если источник даёт RSS, XML, JSON или API, сначала сравните: иногда feed-importer или API-интеграция проще и стабильнее, чем scraping HTML.
Хорошие сценарии
- Миграция собственного старого сайта, где страницы имеют похожий HTML и нужно создать черновики WordPress.
- Партнёрский каталог, где владелец источника разрешил импорт описаний, изображений и ссылок.
- Новостная витрина, где редактор проверяет каждую запись перед публикацией.
- Тестовая база контента для темы, шаблона, поиска, фильтрации или демо-сайта.
- Live-блок с небольшим фрагментом данных, если источник стабилен и shortcode работает через кеш.
Плохие сценарии
Crawlomatic не должен заменять редакционную стратегию. Если задача звучит как "наполнить сайт чем угодно", результат почти всегда будет слабым. Поисковые системы и пользователи плохо реагируют на дубли, машинные пересборки чужих материалов и страницы без добавленной ценности. Плагин также не решит проблему источника, который блокирует запросы, требует авторизацию, активно меняет DOM, отдаёт контент только после сложных пользовательских действий или запрещает повторное использование данных.
Для сайтов с чувствительными ролями пользователей, большим числом авторов и открытой регистрацией особенно важна безопасность. У Crawlomatic были исправления, связанные с обработкой shortcode callbacks и старыми уязвимостями. Поэтому перед установкой нужно проверять не только функции, но и текущую безопасную ветку, роли пользователей, права на публикацию и доступ к настройкам плагина.
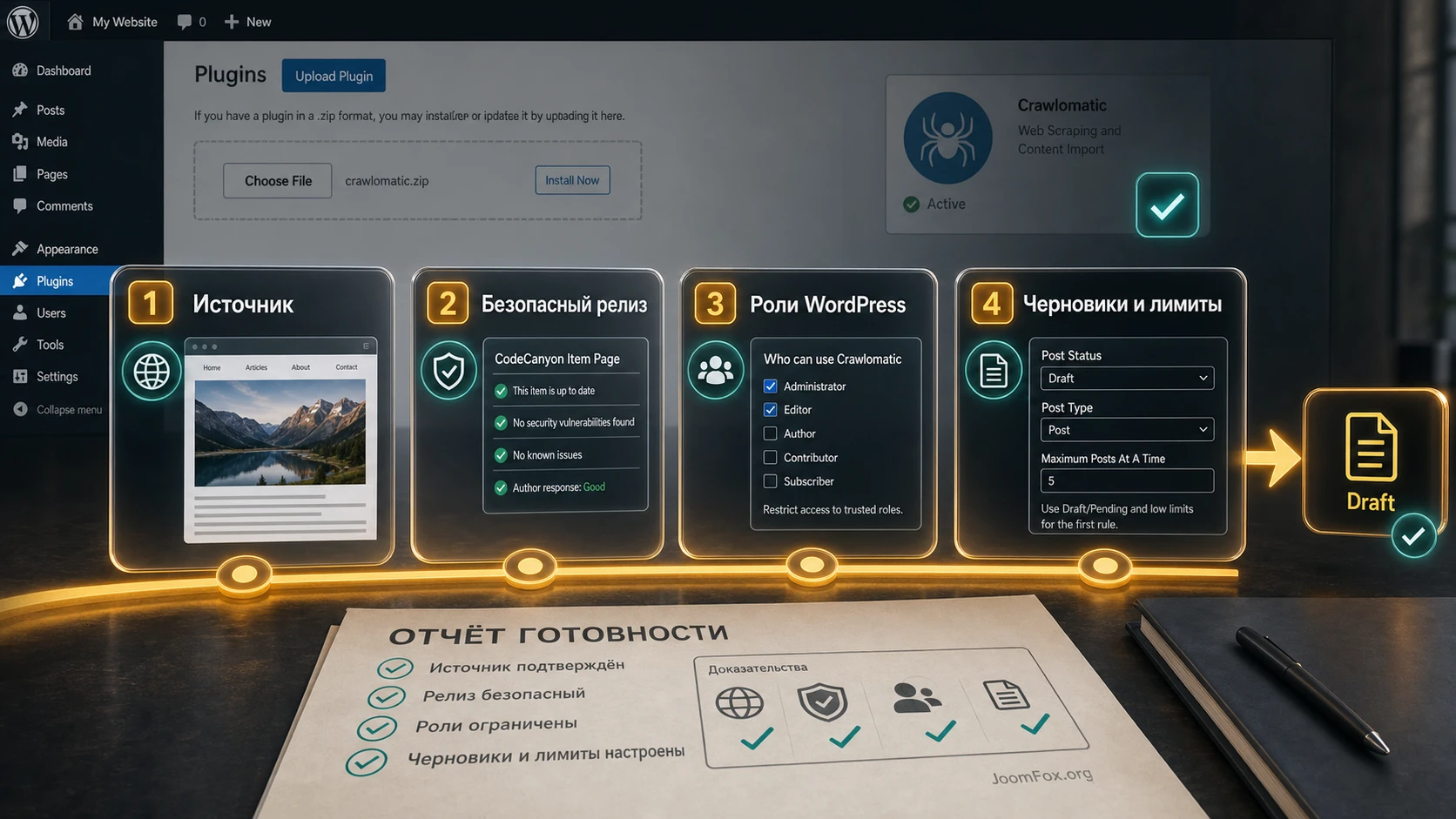
Что проверить перед установкой
Перед установкой Crawlomatic сделайте короткий технический и редакционный аудит. Это занимает меньше времени, чем разбирать сотню неправильно импортированных записей. Начните с тестовой копии сайта. Даже если плагин совместим с текущими версиями WordPress по карточке товара, конкретная тема, builder, кеш-плагин, security-plugin и hosting limits могут влиять на импорт, сохранение изображений и cron-запуски.
Техническая готовность сайта
Проверьте, что у вас есть свежая резервная копия, доступ администратора, возможность отключить плагин через админку или файловый менеджер хостинга, нормальный лимит выполнения PHP и достаточно места для медиафайлов. Crawlomatic может скачивать изображения, создавать attachments и вести логи. Если сайт уже упирается в дисковую квоту, импорт с картинками быстро создаст новую проблему.
- Ставьте плагин сначала на staging или локальную копию, если сайт уже работает с трафиком.
- Проверьте, что ZIP-архив получен из доверенного источника и соответствует актуальному релизу с исправлениями безопасности.
- Ограничьте доступ к настройкам плагина администраторами или доверенными редакторами.
- Проверьте, кто на сайте имеет роли
Author,EditorиAdministrator, особенно если shortcode может использоваться в пользовательском контенте. - Убедитесь, что кеш, firewall и object cache не ломают запуск cron и сохранение медиафайлов.
Готовность источника
Откройте сайт-источник обычным браузером и посмотрите, что именно вы хотите импортировать. Найдите стартовую страницу, список ссылок, пример конечной страницы, основной контейнер текста, заголовок, изображение, дату, категорию. Если вы не можете глазами объяснить, где на странице нужные данные, плагин тоже не сможет стабильно угадать это за вас.
Проверьте robots.txt, условия использования, частоту обновлений и нагрузку. Даже когда технически можно сделать много запросов, это не значит, что нужно. Для корректной работы выбирайте умеренное расписание, малый Max Posts At A Time, кеш для live-фрагментов и понятный user agent. Если сайт отдаёт разный HTML пользователям из разных регионов или требует cookies, тестируйте особенно внимательно.
Контентная рамка
Определите, что будет считаться успешной записью. Например: заголовок не короче пяти слов, основной текст больше заданного минимума, есть featured image, нет блоков навигации, ссылка на источник сохранена, категория назначена, запись попадает в Draft. Эти критерии потом превращаются в настройки: ограничения по словам, required/banned words, query string, шаблон контента и статус публикации.
Установка и первая проверка в админке
Если у вас уже есть ZIP-архив плагина, установка проходит стандартным WordPress-путём: Plugins, Add New, Upload Plugin, выбор архива, установка и Activate. Не нужно прописывать внешние ключи API для базового crawling HTML, но отдельные режимы вроде HeadlessBrowserAPI, внешних переводчиков, прокси или text spinner требуют собственных настроек и должны включаться только при реальной необходимости.
После активации не начинайте с массового расписания. Откройте меню плагина и найдите общие настройки. В документации Crawlomatic описаны Main Settings, logging, timeout для правила, очистка логов, email summary, ограничения публикации и параметры изображений. На первом запуске вам нужны не все функции, а только те, которые защищают сайт от хаоса: логи, черновики, малый лимит, проверяемые селекторы и ограничение источника.
Первичный набор настроек
- Включите логирование правил, но не включайте подробное логирование надолго, потому что оно может быстро увеличить размер логов.
- Поставьте безопасный статус публикации:
DraftилиPending. - Ограничьте число записей за один запуск через
Max Posts At A Time. - Оставьте расписание редким, пока не проверите качество первой партии.
- Включайте копирование изображений локально только если у вас есть права на изображения и достаточно места в медиабиблиотеке.
- Проверьте настройки удаления ссылок, HTML-элементов и внутренних блоков до массового импорта.
Для первого теста удобнее создать отдельную категорию вроде "Импорт - проверка" и отдельного автора. Так вы быстро увидите, какие материалы созданы плагином, не смешаете их с редакционными публикациями и сможете удалить тестовые записи без риска задеть обычный контент.
Как понять, что установка прошла нормально
Нормальная установка не означает, что правило уже работает. Сначала убедитесь, что меню плагина открывается, настройки сохраняются, ошибки PHP не появляются, логи доступны, а запуск тестового правила не приводит к белому экрану или зависанию админки. Если после сохранения настроек появляются ошибки безопасности, странные предупреждения сервера или невозможность записать файлы, остановитесь и проверьте права файловой системы, версию PHP, расширения DOM, mbstring, iconv и json.
Подробная настройка правила Web Crawl to Posts
Главный рабочий экран Crawlomatic - правило импорта. В документации он описан вокруг Scraper Start URL, Schedule, Max Posts At A Time, Post Status, Item Type, Post Author, Active, информации о созданных items и действия Run Now. Ваша задача - собрать правило так, чтобы оно создавало предсказуемый черновик, а не пыталось угадывать весь сайт.
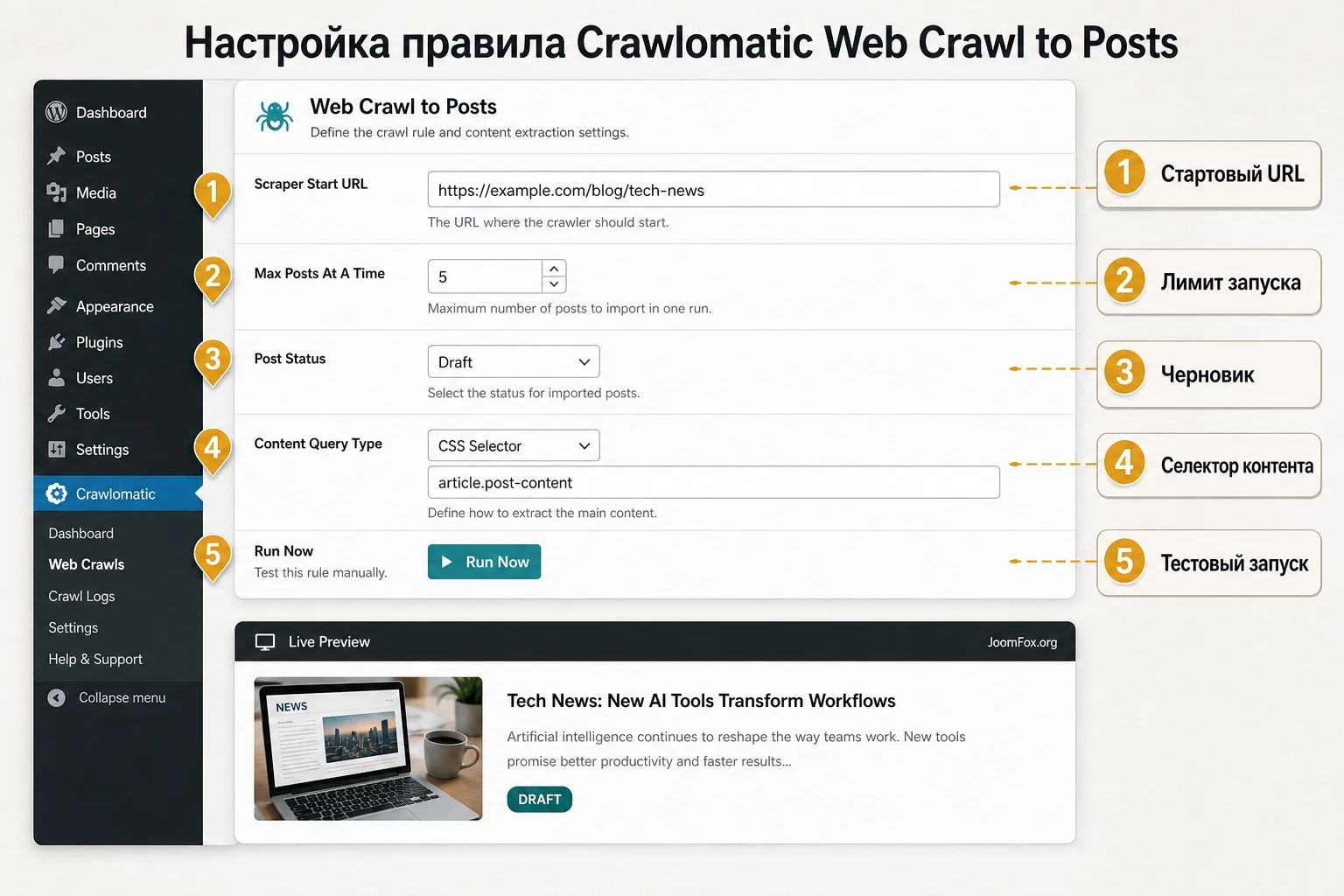
Стартовый URL и глубина crawling
Scraper Start URL - это точка входа. Если указать главную страницу большого сайта, плагин может найти слишком много нерелевантных ссылок. Лучше начинать с конкретного раздела, категории, sitemap-файла или страницы списка, где находятся именно нужные материалы. Если в настройках есть ограничение внешних ссылок, включайте его для большинства сценариев. Документация прямо предупреждает, что разрешение внешних ссылок может привести к непредсказуемым публикациям.
Глубина crawling определяет, насколько далеко плагин пойдёт от стартовой страницы. Для первого правила часто достаточно малой глубины. Большая глубина нужна только если источник устроен как категория -> подкатегория -> материал, и вы понимаете эту структуру. Чем глубже crawling, тем выше риск захватить архивы, страницы тегов, пагинацию комментариев, служебные URL и нерелевантные разделы.
Статус, автор и тип записи
Для рабочего запуска выбирайте тип записи исходя из задачи: обычные материалы - post, статичные страницы - page, каталог или карточки - custom post type, WooCommerce-сценарии - product, если это подтверждено вашей структурой и настройками. Статус Published лучше оставить на потом. Пока правило не проверено на нескольких партиях, самый безопасный статус - черновик.
Автор тоже важен. Если все импортированные материалы идут от отдельного технического автора, их проще фильтровать, проверять, удалять и исключать из внутренних редакционных отчётов. Не используйте реального редактора как автора автопубликаций, если редактор не проверяет каждую запись.
Лимиты и расписание
Max Posts At A Time ограничивает количество создаваемых записей за запуск. Это ваша страховка от ситуации, когда правило нашло сотни ссылок. Расписание лучше включать только после ручного Run Now и проверки результата. Если источник обновляется редко, не ставьте слишком частые запуски. Если источник меняется быстро, сначала подумайте, нужна ли вам публикация каждой перемены или достаточно периодической сводки.
Селекторы для контента, заголовка и изображения
Документация Crawlomatic позволяет задавать query type и query string для основного контента, заголовка, featured image, даты, категорий и тегов. В типовой ситуации CSS selector проще: он похож на то, как вы выбираете блок в инспекторе браузера. XPath полезен, когда нужно добраться до элемента по сложной структуре. Regex оставляйте для крайних случаев, где нет нормального DOM-блока или нужно обработать нестандартный текстовый ответ.
| Метод | Когда использовать | Риск | Проверка |
|---|---|---|---|
| CSS selector | У страницы есть понятные классы или ID для заголовка, статьи, изображения. | Класс может измениться после редизайна источника. | Открыть несколько материалов и убедиться, что selector выбирает один и тот же смысловой блок. |
| XPath | HTML вложенный, нужный блок не имеет удобного class или ID. | Путь может быть хрупким при изменении структуры. | Проверить не одну страницу, а минимум несколько разных материалов источника. |
| Regex | Нужно вытащить данные из текстового ответа или нестандартного фрагмента. | Легко захватить лишнее или сломать правило на исключении. | Тестировать на разных примерах и держать правило в черновиках. |
| Auto | Первичный быстрый тест, когда структура простая. | Автоопределение может взять не тот блок. | Сравнить результат с ручным селектором и логами. |
Шаблон записи и переменные
Шаблон - место, где импорт превращается в читаемую WordPress-запись. В документации перечислены переменные для заголовка, контента, URL, изображения, категорий, тегов и пользовательских HTML-блоков. Не делайте шаблон слишком сложным в первый день. Достаточно вывести заголовок, основной текст, аккуратную ссылку на источник, изображение и, при необходимости, короткую редакционную пометку.
<p>Источник: <a href="/%%item_url%%" rel="nofollow">перейти к оригиналу</a></p>
%%item_content%%
Этот пример не является обязательной формулой. Он показывает принцип: шаблон должен быть прозрачным. Если вы добавляете affiliate keyword replacer, random sentence generator, перевод или text spinner, делайте это позже и только после проверки базового импорта. Чем больше автоматических преобразований включено сразу, тем сложнее понять, где возникла ошибка.
Селекторы, live scraper и shortcode для точечного вывода
Массовые правила создают записи, а live scraper выводит фрагмент данных внутри уже существующей страницы. Для этого используется shortcode [crawlomatic-scraper] или template tag. В документации описаны параметры url, query_type, query, output, cache, timeout, on_error, strip_links, strip_images, glue, eq, lt, gt, basehref и другие. Это мощно, но требует дисциплины.
Если shortcode стоит на публичной странице, каждый посетитель может косвенно запускать обращение к внешнему источнику. Поэтому кеш важен не как "ускоритель", а как защита сайта от лишних запросов. Для статичного или редко меняющегося блока ставьте длинный кеш. Для часто меняющегося блока всё равно не делайте timeout слишком большим, иначе медленный источник будет тормозить вашу страницу.
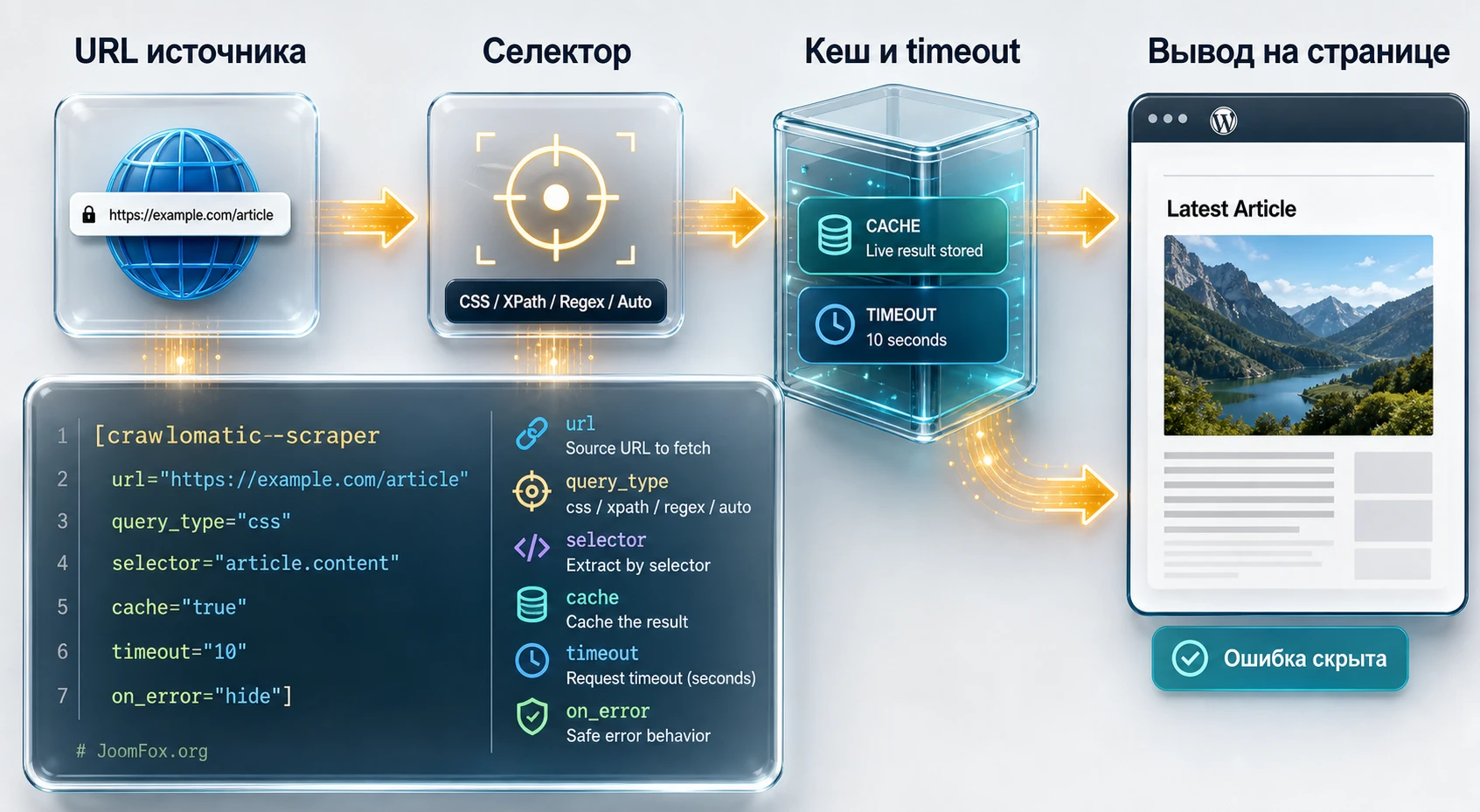
Безопасный пример логики shortcode
Предположим, вы хотите вывести один публичный показатель из собственного источника. Сначала найдите точный selector, затем проверьте результат в черновике, затем настройте output="text", если HTML не нужен. Для ошибки лучше задать нейтральное сообщение или скрытие, чтобы публичная страница не показывала технические подробности.
[crawlomatic-scraper url="https://example.com/status/" query_type="cssselector" query=".status-value" output="text" cache="1440" timeout="3" on_error="Данные временно недоступны"]В реальном HTML статьи выше это просто пример синтаксиса. Не копируйте URL и selector без адаптации. Важнее понять механику: URL должен быть стабильным, selector - точным, кеш - достаточно длинным, ошибка - безопасной для читателя.
Когда shortcode лучше не использовать
Не вставляйте live scraper в шапку сайта, главный экран, меню, checkout, форму заявки или критичный блок, если источник нестабилен. Не используйте его для десятков элементов на одной странице без кеша. Не выводите сырой HTML от чужого сайта, если не проверили, что там нет лишних ссылок, встроенных фреймов, мусорной разметки и нестабильных классов. Для больших импортов лучше использовать правило в черновики, а shortcode оставить для маленьких фрагментов.
Практический пример: импорт раздела в черновики с проверкой результата
Разберём сценарий, который можно безопасно повторить на тестовой копии. Цель - импортировать несколько материалов из собственного старого раздела в WordPress, сохранить их как черновики, подтянуть заголовок, основной текст и изображение, удалить лишние навигационные ссылки, назначить категорию и проверить, что результат не требует ручной чистки с нуля.
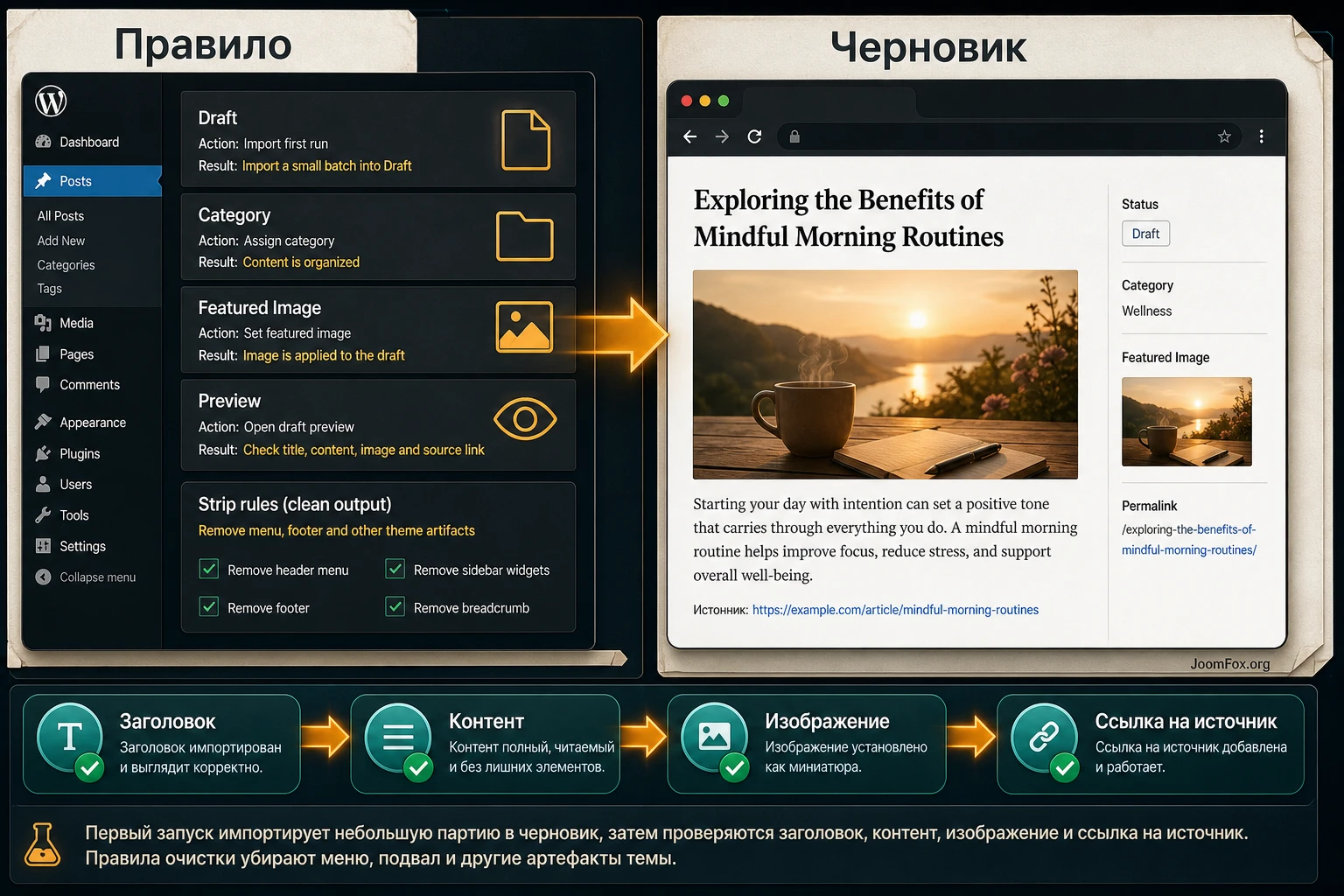
Цель
Получить 3-5 черновиков из старого раздела сайта, где каждая запись имеет нормальный заголовок, основной текст без меню и футера, featured image, категорию "Архив", ссылку на оригинальный URL и статус Draft. Никакой автоматической публикации на первом запуске.
Подготовка
- Создайте категорию "Архив - проверка" или похожую техническую категорию.
- Выберите стартовую страницу, где перечислены ссылки только на нужные материалы.
- Откройте одну конечную страницу источника и найдите selector основного текста.
- Проверьте второй и третий материал, чтобы selector не был уникальным только для одной страницы.
- Подготовьте шаблон записи с ссылкой на источник и переменной основного контента.
Шаги настройки
- Создайте новое правило в
Web Crawl to Postsи вставьте стартовый URL. - Поставьте
Max Posts At A Timeна малое значение, например 3 или 5, чтобы первая партия была контролируемой. - Выберите
Post StatusкакDraftи назначьте технического автора. - Ограничьте crawling внешних ссылок, если источник не требует перехода на другой домен.
- В
Content Query Typeвыберите CSS selector или XPath, а вContent Query Stringукажите найденный блок статьи. - Для заголовка и изображения задайте отдельные selectors только если автоопределение ошибается.
- Включите featured image только при наличии прав на изображения и проверьте, куда они сохраняются в медиабиблиотеке.
- Сохраните правило и запустите
Run Now.
Проверка результата
После запуска откройте список записей WordPress и отфильтруйте черновики по категории или автору. Проверьте каждую запись не только в редакторе, но и через предпросмотр. В редакторе видно, что сохранилось в контенте, а предпросмотр показывает конфликт с темой, shortcodes, lazy images и CSS. Если видите меню, хлебные крошки или блоки комментариев внутри импортированного текста, вернитесь к selector или добавьте strip-правило по class/ID.
Мини-итог: первый запуск считается успешным не тогда, когда появились записи, а когда каждая созданная запись объяснимо соответствует правилам: правильный источник, правильный блок контента, правильный статус, нормальное изображение и отсутствие лишней навигации.
Нюанс с дублями
Если повторный запуск не создал новых записей, это не всегда ошибка. В support-кейсе разработчик объяснял ситуацию, когда все доступные URL уже были опубликованы, поэтому плагин не продолжал импорт, чтобы не создавать дубли. В таком случае проверьте список уже обработанных URL, логи правила, глубину crawling и наличие новых материалов в источнике. Если источник действительно исчерпан, добавьте новые категории или другой стартовый URL, а не пытайтесь заставить правило повторно импортировать те же страницы.
Особые сценарии: новости, каталоги, WooCommerce и миграция
У Crawlomatic широкий набор функций, но разные сценарии требуют разных настроек. Ошибка многих пользователей - делать одно универсальное правило для всего. Лучше создавать отдельные правила под разные источники и задачи. Так проще контролировать selector, категорию, шаблон, статус, расписание, featured image и ограничения по словам.
Новостной или справочный раздел
Для новостной витрины главные настройки - регулярность, фильтрация по словам, длина контента, category mapping и статус черновика. Не импортируйте всё подряд. Включите required words, если нужно брать только материалы по узкой теме, и banned words, если источник смешивает разные рубрики. В шаблон добавьте ссылку на источник, а редактору оставьте место для собственного вступления или комментария.
Каталог и WooCommerce
Marketplace-страница Crawlomatic упоминает WooCommerce-сценарии, включая извлечение цен и вариаций из определённых источников. Это не значит, что любой магазин импортируется идеально. Товары сложнее обычных статей: цена, вариации, наличие, атрибуты, изображения галереи, описание, SKU и налоговые настройки должны согласоваться с вашим магазином. Начинайте с тестового товара, не публикуйте автоматически, проверяйте корзину и карточку товара, а спорные поля оставляйте на ручное заполнение.
Миграция собственного архива
Для миграции старого сайта Crawlomatic может быть удобнее ручного копирования, если HTML повторяемый. Но здесь важна чистота результата. Сначала импортируйте небольшой раздел, затем проверьте внутренние ссылки, изображения, заголовки, таблицы, кодовые блоки и старые embeds. Если старый сайт использовал нестандартную разметку, лучше добавить strip-правила и шаблон, чем потом редактировать сотни записей.
Обновляемые материалы
В функциях Crawlomatic есть возможность обновлять созданные записи, если исходная страница изменилась, и переводить запись в черновик, если исходный URL недоступен. Эти режимы полезны для каталогов и справочников, но включайте их аккуратно. Если редактор уже дополнил импортированную запись вручную, автоматическое обновление может затереть ценную правку. Безопасный подход - сначала тестовая категория, потом отдельное правило для материалов, где автоматическое обновление действительно нужно.
Как проверять качество и не вредить SEO
Автоматизация публикаций не должна превращать сайт в склад повторов. Даже если плагин корректно импортирует контент, поисковая и пользовательская ценность зависит от вашей редакционной обработки. Для справочных страниц добавляйте собственное вступление, контекст, сравнение, практическую проверку, локальные примеры, уточнения и ссылки на связанные материалы. Если импорт нужен только для внутреннего архива, закрывайте такие записи от индексации или держите их вне публичной навигации до обработки.
Проверка одной записи
Откройте черновик и пройдите по короткой цепочке: заголовок, первый абзац, основной блок, изображение, ссылка на источник, категория, excerpt, canonical, внутренние ссылки, мобильный предпросмотр. Если в тексте есть обрывки меню, рекламные кнопки, cookie banners, social widgets, повторяющиеся блоки автора или комментарии, selector выбран слишком широко. Если текст пустой или короткий, source layout изменился или query string не подходит.
Проверка группы записей
После первой партии посмотрите не только отдельные публикации, но и архив категории. Заголовки не должны повторяться, изображения не должны быть одинаковыми placeholder-картинками, даты не должны создавать ложную хронологию, а excerpt не должен состоять из служебного текста. Если несколько записей выглядят одинаково, остановите правило и улучшите селектор, вместо того чтобы удалять дубли вручную после каждого запуска.
Настройки, которые помогают держать качество
- Minimum Content Word Count помогает не публиковать пустые или слишком короткие импортированные страницы.
- Maximum Content Word Count полезен, если источник иногда отдаёт целую страницу с лишними блоками.
- Banned Words List помогает отсеять служебные или неподходящие материалы.
- Required Words List ограничивает импорт тематикой, если источник смешивает разные рубрики.
- Skip Posts That Do Not Have Images уместен для каталогов и визуальных рубрик, но не нужен для обычных текстовых заметок.
- Enable Logging for Rules помогает понять, почему правило сработало именно так.
Частые проблемы Crawlomatic и диагностика
Проблемы с Crawlomatic чаще всего появляются не из-за одной причины, а из-за связки: источник изменил HTML, серверу не хватает времени, selector берёт не тот блок, правило уже импортировало все URL, кеш показывает старый результат, а логи слишком короткие или слишком подробные. Ниже - практическая диагностика без паники и без удаления всего правила.
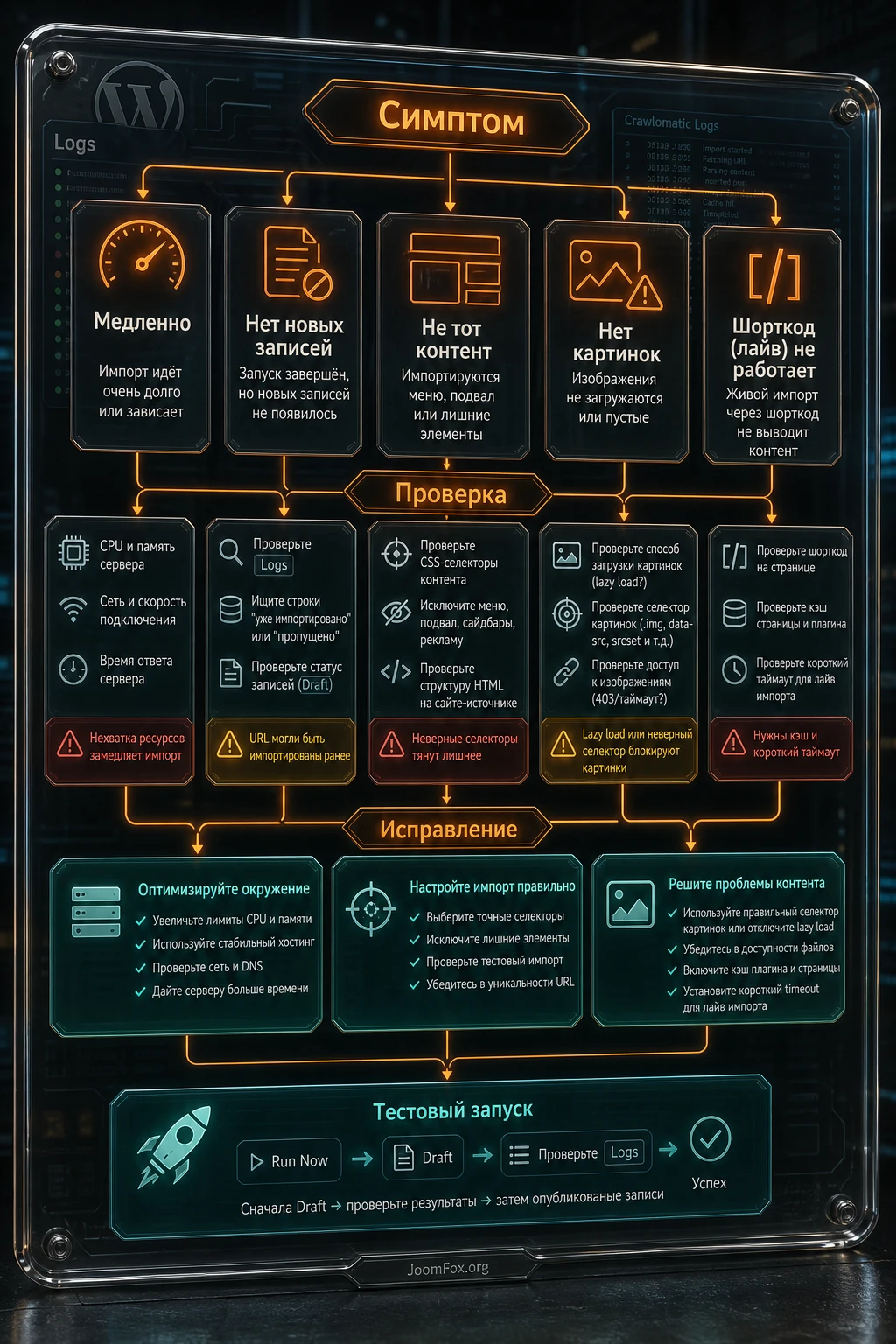
Правило запускается, но записи не появляются
Симптом: правило показывает запуск или жёлтый статус, но новых записей нет. Возможная причина - все найденные URL уже были импортированы, стартовая страница больше не содержит новых ссылок, глубина crawling слишком мала или фильтры отсекают все материалы. Сначала проверьте логи и список уже созданных записей по техническому автору. Затем откройте стартовый URL в браузере и убедитесь, что там действительно есть новые ссылки.
Исправление: добавьте новый стартовый URL, расширьте список категорий источника, временно уменьшите фильтры, но не отключайте защиту от дублей вслепую. Если правило перестало работать после изменения источника, проверьте selector ссылок и основной content query.
Импорт идёт слишком медленно
Симптом: большая партия импортируется десятки минут, правило зависает или сервер обрывает процесс. Support-разработчик указывал, что скорость зависит от CPU, памяти, сети, серверных лимитов и числа запросов. Проверьте Max Posts At A Time, timeout, глубину crawling, изображения, headless-режимы и количество запросов к источнику. Если вы импортируете сотни материалов, малый лимит и несколько запусков безопаснее одного огромного процесса.
Исправление: снизьте число записей за запуск, отключите лишние запросы, не копируйте изображения на первом тесте, настройте кеш для live scraper, проверьте max execution time у хостинга. Если источник медленный, не увеличивайте timeout бесконечно: это может перенести проблему на ваш сайт.
В записи попадает меню, футер или рекламный блок
Симптом: контент импортирован, но внутри записи есть навигация, похожие статьи, кнопки, блоки комментариев или footer. Причина почти всегда в слишком широком selector или автоопределении. Проверьте конечную страницу источника через инспектор и найдите более узкий контейнер статьи. Если нужный блок содержит лишние вложенные элементы, используйте strip по ID или class.
Исправление: замените auto query на CSS selector или XPath, добавьте remove/strip-правила, импортируйте заново 1-2 черновика. Не пытайтесь чистить каждую запись вручную, пока правило продолжает создавать тот же мусор.
Featured image не сохраняется или берётся не та картинка
Симптом: у черновиков нет изображения, вместо изображения берётся логотип, иконка соцсети или первая рекламная картинка. Проверьте настройку автоматического featured image, query для изображения, lazy load атрибуты и право копировать картинку локально. Иногда сайт хранит реальный URL изображения не в src, а в lazy load атрибуте. В официальном видео этот сценарий разбирается как отдельная тема.
Исправление: укажите более точный featured image selector, настройте lazy load tag, временно отключите копирование картинок для диагностики, а затем проверьте медиабиблиотеку и предпросмотр. Если права на изображения неясны, не сохраняйте их автоматически.
Live scraper тормозит страницу
Симптом: страница с shortcode долго открывается или периодически показывает ошибку. Причина - внешний источник отвечает медленно, кеш короткий или выключен, timeout слишком большой, на странице стоит несколько shortcode. Проверьте, сколько live-запросов выполняется на одну страницу, и насколько часто меняются данные.
Исправление: увеличьте cache, уменьшите timeout, задайте нейтральный on_error, оставьте на странице только действительно нужные live-фрагменты. Если блок критичен для конверсии, лучше хранить данные в WordPress как черновики или custom fields, а не тянуть их при каждом просмотре.
После обновления изменилось поведение правила
Симптом: после обновления плагина или источника правило стало брать другой контент. Проверьте changelog, логи, selectors и настройки callback/shortcode. Из-за исправлений безопасности некоторые рискованные способы обработки callbacks могут измениться. Это нормальная цена безопасного обновления, но её нужно учитывать на тестовой копии.
Исправление: протестируйте правило на staging, сверните спорные callbacks, замените сложную обработку на безопасный selector или редакторскую проверку, обновите шаблон записи. Если правило зависит от нестандартного PHP callback, не переносите его на production без ревью кода.
Безопасные улучшения и рабочие привычки
Для Crawlomatic полезнее не кодовые хаки, а аккуратная эксплуатация. Официальные источники подтверждают много настроек, но не дают универсального безопасного snippet для каждого сайта. Поэтому ниже - не правка ядра и не вмешательство в файлы плагина, а набор привычек, которые снижают риск.
Разделяйте правила по источникам
Не делайте одно правило на десять сайтов. У каждого источника своя структура, частота обновлений, selector, изображение и юридический контекст. Отдельные правила проще отключать, сравнивать и исправлять. Если один источник сломался, остальные продолжат работать.
Держите импорт в черновиках до стабильности
Даже если первые 3 записи выглядят нормально, источник может иметь исключения. Проверьте разные типы страниц: короткую заметку, длинную статью, страницу без изображения, страницу с видео, страницу с галереей. Только после нескольких чистых запусков можно думать о Pending или автоматической публикации.
Ограничьте роли и shortcode
Если на сайте несколько авторов, не разрешайте всем использовать scraping shortcode без понимания последствий. История security advisories по Crawlomatic показывает, что shortcode callbacks и права пользователей нельзя считать мелочью. Старайтесь, чтобы настройки плагина и публикация материалов через scraping оставались в руках администратора или доверенного редактора.
Следите за логами, но чистите их
Логи помогают понять, почему правило пропустило материал, где источник не ответил, какой URL уже обработан и что произошло при запуске. Но подробные логи могут расти быстро и иногда содержать чувствительные детали запросов. Включайте detailed logging для диагностики, затем возвращайтесь к обычному уровню и настройте очистку старых логов.
Видео по расширенной настройке
Официальный видеоурок CodeRevolution по Crawlomatic полезен как визуальное дополнение к этой статье. В нём показываются lazy loaded images, выбор контента, переход от single к serial scraping, базовые и advanced settings в Web Crawl to Posts, pagination, Custom Shortcode Creator, Activity and Logging, Main Settings, proxy, image options, WooCommerce price modifications и live scraping shortcode. Если вы впервые настраиваете сложное правило, ролик лучше смотреть рядом с тестовой копией сайта, а не на production.
Практически важные отрезки: начало показывает одинарный импорт, далее идут lazy images и выбор нужного блока контента, середина ролика разбирает advanced settings, pagination и extraction fields, ближе к финалу идут logging, proxy, image options, WooCommerce price modifications и shortcode. Это закрывает intent "как пользоваться CodeCanyon Crawlomatic" лучше, чем короткий обзор без экранов.
FAQ по настройке и использованию Crawlomatic
Можно ли сразу публиковать импортированные записи?
Технически можно выбрать опубликованный статус, но для первого правила это плохая практика. Начинайте с Draft или Pending, проверьте несколько партий, исправьте selectors и только потом решайте, можно ли доверить правилу автоматическую публикацию.
Что выбрать: CSS selector, XPath или regex?
Для большинства HTML-страниц начните с CSS selector. XPath выбирайте, если структура сложная и классы не помогают. Regex используйте только тогда, когда DOM-методы не подходят или источник отдаёт текстовый формат. Если regex можно заменить selector, обычно лучше заменить.
Почему Crawlomatic не создаёт новые записи после повторного запуска?
Частая причина - найденные URL уже импортированы, и плагин не создаёт дубли. Проверьте логи, список записей, стартовый URL и наличие новых ссылок на источнике. Если источник исчерпан, добавьте другой раздел или sitemap-правило вместо отключения защиты от дублей.
Можно ли использовать плагин для WooCommerce?
В функциях и changelog Crawlomatic есть WooCommerce-сценарии, включая цены, вариации и изображения. Но товары требуют более строгой проверки, чем статьи. Тестируйте на staging, держите статус черновика, проверяйте карточку товара, вариации, цену, изображение и поведение корзины.
Нужно ли включать headless-режимы?
Только если источник действительно загружает нужный контент через JavaScript и обычный запрос не видит данных. Headless-режимы усложняют серверную нагрузку и диагностику. Если источник отдаёт нормальный HTML, начинайте без них.
Как не перегрузить свой сайт live shortcode?
Используйте кеш, короткий timeout, нейтральный on_error и минимум shortcode на странице. Если данные важны для каждой загрузки страницы, лучше сохранять их заранее через правило или custom field, а не обращаться к внешнему источнику при каждом просмотре.
Что проверить по безопасности перед установкой?
Проверьте актуальный релиз, changelog и security advisories, ограничьте роли пользователей, не давайте недоверенным авторам возможность вставлять сложные scraping shortcode, держите резервную копию и тестируйте обновления на копии сайта. Для старых версий особенно важно не откладывать обновления безопасности.
Когда Crawlomatic не подойдёт?
Если источник запрещает повторное использование, HTML постоянно меняется, данные доступны только после сложной авторизации, нужен официальный API-workflow или редакторская ценность не добавляется, лучше выбрать другой подход. Иногда RSS/XML importer, API-интеграция или ручная редакционная подготовка дадут более стабильный результат.
Когда CodeCanyon Crawlomatic будет удачным выбором
CodeCanyon Crawlomatic стоит использовать, если у вас есть понятный источник, повторяемая структура страниц, правомерная причина импортировать данные, тестовая копия сайта и готовность проверять первые партии вручную. Сильная сторона плагина - гибкость: seed URL, crawling depth, selectors, шаблоны, статусы, featured images, logging, live scraper shortcode и специальные сценарии для каталогов или WooCommerce. Слабая сторона этой же гибкости - риск ошибиться в настройке и получить мусор вместо базы знаний.
Оптимальная стратегия проста: поставить плагин на тестовой копии, создать маленькое правило, держать записи в черновиках, проверить selector на нескольких страницах, включить логи, оценить нагрузку и только потом расширять расписание. Если в процессе вы понимаете, что источник лучше отдаёт RSS, API или JSON, не держитесь за scraping ради самого scraping. Выбирайте тот способ, который даёт меньше ошибок и больше контроля.
Если после этого подход кажется подходящим для вашего сайта, можно перейти к блоку загрузки и получить файл CodeCanyon Crawlomatic, затем повторить настройку сначала на копии сайта. Так вы получите не просто установленный плагин, а управляемый процесс импорта, где каждая созданная запись проходит понятную проверку качества.

