Как управлять доступом ИИ-сканеров к контенту сайта
Искусственный интеллект кардинально меняет принципы поиска информации в интернете, внедряя новые алгоритмы автоматизированного сбора данных. Специализированные ИИ-сканеры непрерывно анализируют миллионы веб-сайтов для обучения глобальных языковых моделей и предоставления мгновенных, точных ответов конечным пользователям. Понимание скрытых механизмов работы этих ботов позволяет владельцам цифровых ресурсов эффективно управлять доступом к своему контенту и надежно защищать конфиденциальную информацию. Грамотная настройка разрешений и ограничений для краулеров становится важнейшим элементом современной стратегии технической поисковой оптимизации и сетевой безопасности.

Веб-сайты создаются не просто ради публикации текстов, а метаданные настраиваются не ради забавы - все эти элементы работают в единой связке, чтобы страницы могли быть легко найдены целевой аудиторией. На протяжении многих лет традиционный поиск Google оставался главным источником органического трафика и порталом к этой видимости, во многом благодаря своим классическим поисковым роботам (веб-краулерам).
Начиная с конца 1990-х годов, Googlebot и аналогичные традиционные сканеры методично обходили сайты, загружали HTML-страницы и индексировали их, чтобы помочь людям находить нужную информацию. По состоянию на начало 2024 года, на долю Google приходилось более 63% всего веб-трафика в США, который распределялся между ведущими мировыми доменами. Это формировало понятные правила игры для специалистов по SEO-продвижению.
Однако сейчас ситуация стремительно меняется. Согласно недавним масштабным исследованиям рынка, половина пользователей интернета теперь предпочитает обращаться к ИИ-инструментам, таким как ChatGPT, Claude, Gemini или Perplexity, чтобы получить мгновенные, структурированные ответы без необходимости переходить по десяткам ссылок. Более того, даже сам Google активно внедряет сгенерированные нейросетью сводки прямо в результаты поиска через функции AI Overviews.
За этими новыми интеллектуальными интерфейсами стоит быстрорастущий класс ботов, известных как ИИ-сканеры (AI crawlers). Для администраторов проектов, работающих на базе системы управления контентом WordPress, понимание того, как эти новые системы получают доступ к опубликованным материалам и используют их, сегодня важно как никогда прежде.
Что такое ИИ-сканеры?
ИИ-сканеры - это специализированные автоматизированные программы-боты, которые сканируют общедоступные веб-страницы. По своей архитектуре они похожи на классические роботы поисковых систем, но созданы совершенно с другой целью. Вместо того чтобы индексировать страницы для ранжирования в традиционной поисковой выдаче по ключевым словам, они собирают гигантские массивы текстовых данных для обучения больших языковых моделей (LLM) или же для предоставления актуальной, свежей информации в ответ на текущие запросы пользователей ИИ-чатов.
В широком смысле все существующие ИИ-сканеры можно разделить на две основные категории:
- Обучающие сканеры (Training crawlers): К этой группе относятся такие известные боты, как GPTBot (от компании OpenAI) и ClaudeBot (от Anthropic). Их главная задача - массовый сбор исторических и актуальных данных, которые затем используются инженерами для тренировки нейросетей, чтобы те могли точнее формулировать мысли, понимать контекст и отвечать на сложные вопросы.
- Сканеры данных в реальном времени (Live retrieval crawlers): Ярким примером является ChatGPT-User. Эти боты обращаются к веб-сайтам «на лету», ровно в тот момент, когда пользователь задает вопрос, требующий самых свежих данных (например, проверка текущей цены товара, чтение свежих новостей или актуальной технической документации).
Существуют и другие роботы, например PerplexityBot или AmazonBot, которые создают собственные гибридные индексы или поисковые системы, чтобы снизить свою зависимость от сторонних источников информации (таких как индекс Google Search или Bing). И хотя конечные бизнес-цели у этих корпораций различаются, их боты имеют одну общую черту: они активно запрашивают, скачивают и анализируют контент с миллионов веб-сайтов.
Как работают ИИ-сканеры на техническом уровне
Когда ИИ-сканер посещает целевой сервер, процесс взаимодействия обычно строится по следующему предсказуемому сценарию:
- Бот отправляет базовый HTTP-запрос (обычно
GET) к URL-адресу страницы. При этом бот не совершает никаких пользовательских действий - он не взаимодействует с элементами интерфейса, не прокручивает страницу и не инициирует события DOM. - Сканер получает и анализирует только исходный HTML-код, который сервер возвращает в первом ответе. В большинстве случаев он не ждет загрузки или выполнения клиентского JavaScript.
- Система извлекает все доступные ссылки
<a href="/...">, пути к изображениям<img src="/...">, скриптам<script src="/...">и другим ресурсам, после чего добавляет внутренние (а иногда и внешние) URL в свою очередь для дальнейшего сканирования. Часто такие боты проверяют даже неработающие ссылки, генерируя на сервере ошибки 404 (Not Found). - Бот может попытаться загрузить связанные медиафайлы, CSS-стили или скрипты, но исключительно как исходные ресурсы для анализа текста или метаданных, а не для визуального рендеринга и отрисовки дизайна страницы.
- Этот процесс повторяется рекурсивно, переходя по всем найденным ссылкам, чтобы составить полную карту структуры сайта.
Важное техническое замечание: Поскольку большинство ИИ-сканеров не выполняют код JavaScript, любой контент, который загружается динамически через AJAX или создается с помощью современных компонентов React/Vue на стороне клиента, часто остается для них абсолютно невидимым. Для сравнения, современный Googlebot обладает полноценным движком рендеринга (на базе Chromium) и индексирует именно то, что в итоге видит живой посетитель в окне своего браузера.
Тем не менее, эти технологические ограничения постепенно исчезают, так как алгоритмы машинного обучения развиваются чрезвычайно быстро. В настоящее время большинство ИИ-ботов работают скорее как быстрые, легковесные парсеры (скрейперы), нежели как полноценные браузерные движки.
Взаимодействие ИИ-сканеров с сайтами на WordPress
Платформа WordPress представляет собой систему, работающую на стороне сервера (Server-Side Rendering). Она использует язык программирования PHP для динамической генерации полных HTML-страниц еще до того, как они будут отправлены в браузер пользователя или боту. Когда сканер заходит на ресурс под управлением WordPress, он сразу получает в ответе всё необходимое: основной текстовый контент, иерархию заголовков, структурированные метаданные и навигационные меню.
Именно эта архитектура серверного рендеринга делает подавляющее большинство сайтов на WordPress максимально дружелюбными к любым краулерам (SEO-friendly). Будь то классический Googlebot или новейший парсер от OpenAI, они могут легко сканировать структуру и беспрепятственно анализировать опубликованный материал. Фактически, эта легкость сканирования является одной из главных причин, почему проекты на базе WordPress традиционно показывают превосходные результаты как в классическом поиске, так и в новых платформах ответов на базе искусственного интеллекта.
Стоит ли разрешать ИИ-сканерам доступ к вашему контенту?
По умолчанию ИИ-сканеры уже могут беспрепятственно читать большинство WordPress-сайтов. Главный стратегический вопрос заключается не в том, могут ли они это делать, а в том, какую именно часть информации им стоит предоставить, и как грамотно контролировать эту видимость.
В индустрии контент-маркетинга и цифрового бизнеса сейчас ведутся горячие дискуссии на эту тему. Этот вопрос затрагивает информационные статьи в блогах, корпоративную документацию, целевые посадочные страницы (Landing Pages) - по сути, любые тексты, опубликованные в открытом доступе. Многие эксперты советуют «писать тексты для машин», поскольку нейросети все чаще извлекают данные в реальном времени и, что самое важное, теперь добавляют в свои ответы активные ссылки на первоисточники. Присутствие бренда в ответах LLM-моделей становится столь же желанным, как и попадание на первую страницу Google.
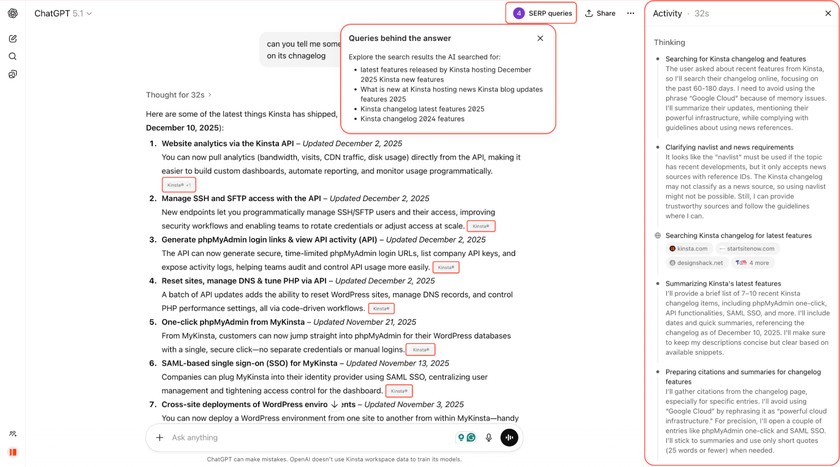
Хотя технология еще формируется, ИИ-сканеры уже оказывают прямое влияние на то, какую информацию люди получают, задавая вопросы в сети. И этот новый канал привлечения аудитории может иметь решающее значение для бизнеса.
Показателен пример генерального директора платформы Vercel, который поделился статистикой: переходы из чатов ChatGPT составили почти 10% от всех новых регистраций в их сервисе, хотя всего полгода назад этот показатель не превышал 1%. Это наглядно демонстрирует, насколько быстро ИИ-рефералы (ссылки из нейросетей) могут превратиться в мощный и независимый канал привлечения клиентов.
Масштаб распространения ИИ-сканеров также впечатляет. По данным аналитики от Cloudflare, ИИ-боты обращаются примерно к 39% из миллиона самых популярных сайтов интернета. Однако лишь около 3% владельцев этих ресурсов предприняли реальные шаги по блокировке или ограничению такого специфического трафика.
Таким образом, даже если администратор сайта еще не принял окончательного решения о политике доступа, ИИ-сканеры почти наверняка уже регулярно индексируют проект.
Разрешить или заблокировать: стратегия принятия решения
Универсального ответа на этот вопрос не существует, так как каждый веб-проект уникален. Однако можно опираться на следующий базовый фреймворк для принятия решения:
- Строгая блокировка: Рекомендуется закрывать от сканеров системные, конфиденциальные или малоценные пути, такие как
/login(страницы входа),/checkout(корзина и оформление заказа),/admin(панель управления) или внутренние дашборды. Индексация этих разделов не приносит никакой пользы для видимости бренда и лишь впустую расходует ресурсы и пропускную способность сервера. - Открытый доступ: Целесообразно разрешать сканирование для «информационного контента» - статей в блогах, подробной документации, описаний продуктов, характеристик товаров и страниц с тарифными планами. Именно эти страницы имеют наивысший шанс быть процитированными в ответах искусственного интеллекта, что приведет на сайт качественный, целевой трафик.
- Индивидуальный подход для платного контента: Для премиальных материалов требуется стратегическое решение. Если сам контент является основным продуктом (например, эксклюзивные новости, закрытые аналитические исследования, платные онлайн-курсы), то неограниченный доступ ИИ-ботов к таким текстам может позволить нейросетям бесплатно пересказывать этот материал пользователям, что напрямую подорвет бизнес-модель.
Индустрия также начинает предлагать новые инструменты монетизации. Например, тестируются модели Pay Per Crawl (оплата за сканирование), которые позволят владельцам сайтов взимать микроплатежи с ИИ-компаний за право доступа к их базам данных. Хотя такие инициативы пока находятся на стадии закрытого тестирования, идея получает мощную поддержку со стороны крупных новостных издателей, желающих жестко контролировать использование своей интеллектуальной собственности.
С другой стороны, многие специалисты по маркетингу проявляют осторожность. Блокировка всех ИИ-ботов по умолчанию может привести к полному исчезновению сайта из ответов нейросетей, что критично для бизнеса, зависящего от широкого охвата. На данный момент наиболее прагматичным подходом является политика выборочной открытости: сохранение открытого доступа к полезным статьям, строгая защита служебных разделов и регулярный пересмотр правил по мере развития технологий.
Как управлять доступом ИИ-сканеров на сайтах WordPress
Если присутствие нейросетевых ботов на проекте вызывает опасения, или требуется тонкая настройка их поведения, администратор WordPress обладает полным набором инструментов для возврата контроля над ситуацией.
Существует три основных, проверенных способа управления доступом ИИ-сканеров:
- Ручное редактирование системного файла
robots.txt. - Использование специализированных плагинов WordPress для автоматизации процесса.
- Применение защиты на уровне сети (например, защита от ботов Cloudflare).
Далее каждый из этих методов разобран максимально подробно.
Вариант 1: Блокировка ИИ-сканеров вручную через файл robots.txt
Файл robots.txt - это текстовый документ, размещенный в корневой директории сервера, который сообщает ботам, какие разделы сайта им разрешено сканировать, а какие - категорически запрещено. Большинство добросовестных, легальных ИИ-сканеров, принадлежащих крупным корпорациям (GPTBot от OpenAI, Claude-Web от Anthropic, Google-Extended), строго соблюдают эти правила (директивы).
Администратор может полностью заблокировать конкретных ботов, предоставить им полный доступ или ограничить парсинг определенных директорий. Например, чтобы полностью запретить доступ ключевым ИИ-ботам ко всему сайту (что, как правило, не рекомендуется для открытых проектов), в файл robots.txt необходимо добавить следующий код:
User-agent: GPTBot Disallow: / User-agent: Claude-Web Disallow: / User-agent: Google-Extended Disallow: /
Если же стратегическая цель - разрешить полный доступ для бота от OpenAI, чтобы бренд упоминался в ответах ChatGPT, директива будет выглядеть так:
User-agent: GPTBot Disallow:
Для блокировки исключительно служебных разделов сайта, где присутствие краулеров не несет никакой информационной пользы (например, страница авторизации пользователей), применяется точечное ограничение:
User-agent: GPTBot Disallow: /login/
Такая выборочная блокировка является самым профессиональным подходом. Чувствительные пути (такие как /wp-admin/, /cart/ или /checkout/) всегда должны быть скрыты. В то же время каталоги товаров, обзоры функций и разделы помощи остаются открытыми для генерации цитат и реферальных переходов.
Внести изменения в файл robots.txt на WordPress можно несколькими путями:
- С использованием популярных SEO-плагинов (например, Yoast SEO или Rank Math, перейдя в раздел «Инструменты» -> «Редактор файлов»).
- С помощью плагинов файлового менеджера, устанавливаемых прямо в панель администратора.
- Путем прямого подключения к серверу по протоколу FTP/SFTP и редактирования файла в любом текстовом редакторе.
Вариант 2: Использование плагинов WordPress
Для пользователей, которые предпочитают не вмешиваться в системные файлы напрямую или ищут более быстрый и безопасный способ управления сканерами, созданы специальные плагины, позволяющие настроить защиту буквально в несколько кликов мыши.
Существуют плагины, которые содержат встроенную поддержку блокировки ИИ-ботов. В их интерфейсе администратор может с помощью удобных переключателей выбирать, каким именно ботам запретить доступ. Как правило, базы данных таких плагинов постоянно обновляются, и большинство известных ИИ-ботов (таких как парсеры GPT и Claude) могут блокироваться по умолчанию.
Особое внимание стоит уделить боту Google-Extended. Его блокировка обычно настраивается отдельно, и важно понимать ключевой нюанс: запрет на обход сайта для Google-Extended останавливает использование текстов для обучения нейросетей Google, но при этом никак не влияет на позиции сайта и его видимость в классической поисковой выдаче Google Search.
Специализированные решения (например, плагины категории "Block AI Crawlers") созданы исключительно с одной целью - дать владельцам независимых ресурсов полный контроль. Они автоматически добавляют правильные директивы Disallow в виртуальный robots.txt для более чем десятков известных нейросетевых ботов без необходимости ручной настройки конфигураций. Это легковесные решения с открытым исходным кодом, которые не нагружают базу данных сервера.
Важный нюанс: Если на сервере физически создан текстовый файл robots.txt (вместо виртуального, который генерируется ядром WordPress «на лету»), большинство плагинов не смогут внести в него изменения из-за прав доступа. В таком случае потребуется либо удалить физический файл, позволив плагину работать с виртуальным, либо перенести настройки вручную.
Вариант 3: Использование блокировщика ботов от Cloudflare
Если проект на WordPress использует CDN и DNS-сервисы от Cloudflare (что является современным стандартом для ускорения и защиты сайтов), администратор получает в свое распоряжение сверхмощный инструмент блокировки десятков известных и скрытых ИИ-ботов на уровне сети передачи данных.
Недавно Cloudflare запустила выделенную функцию защиты от ИИ-скрейперов и краулеров, которая доступна даже на бесплатных тарифных планах. В отличие от метода с robots.txt (который полагается на честность разработчиков бота), Cloudflare анализирует сетевые сигналы и блокирует паразитный трафик еще до того, как он достигнет сервера сайта. Это защищает даже от тех парсеров, которые маскируются под обычных пользователей или подменяют свои идентификаторы (User-Agent).
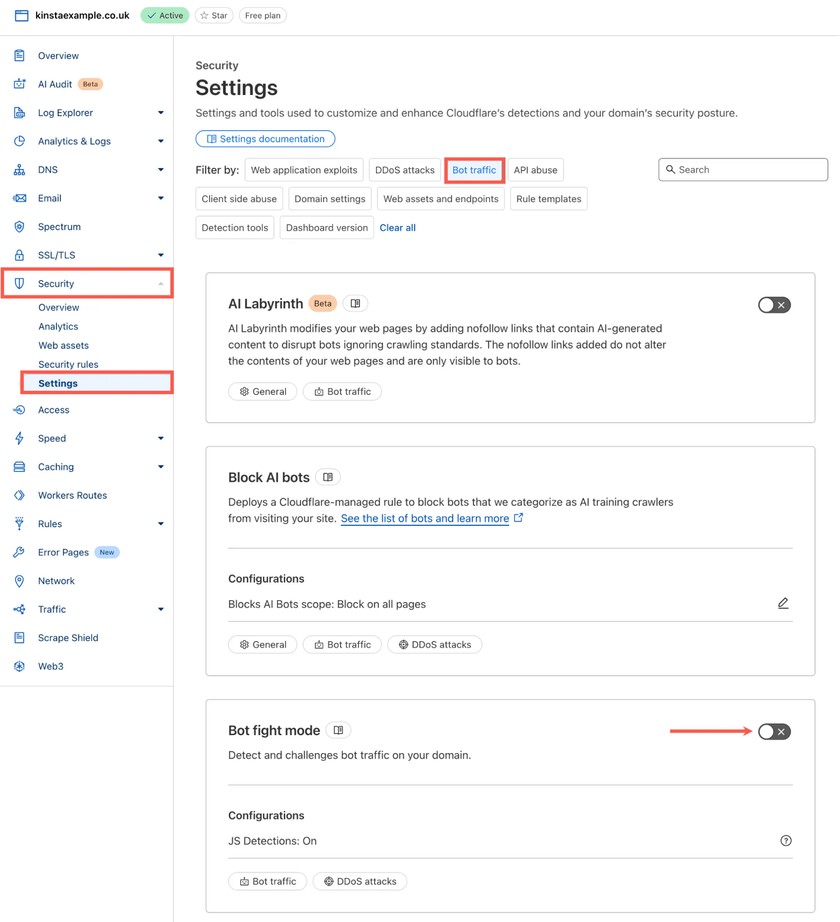
Активация базовой защиты выполняется в несколько шагов:
- Необходимо авторизоваться в панели управления Cloudflare.
- Перейти в раздел Безопасность (Security) -> Настройки (Settings).
- В блоке фильтрации найти опцию Трафик ботов (Bot traffic).
- Включить переключатель Bot fight mode (Режим борьбы с ботами).
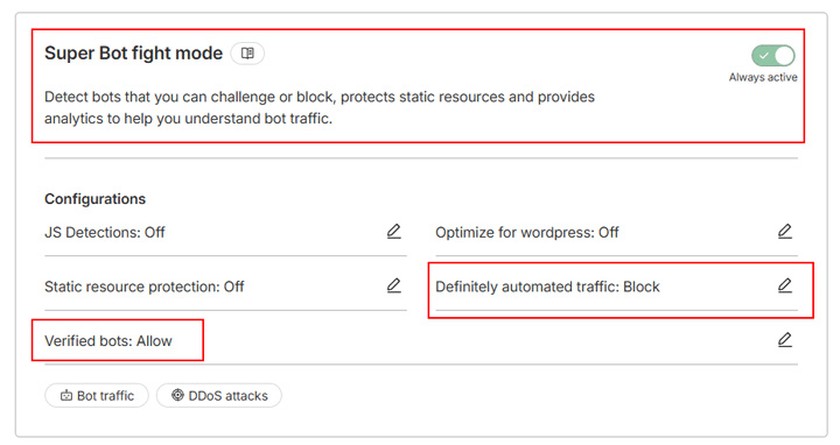
Для пользователей платных тарифов Cloudflare открывается доступ к продвинутому модулю Super Bot Fight mode. Это расширенная версия защиты, предоставляющая гибкие возможности аналитики и тонкой настройки правил. Она базируется на сложной эвристике и внедрении JavaScript-проверок (challenge) в браузер посетителя. Это позволяет выявлять так называемые «безголовые браузеры» (headless browsers), скрытые скрипты для автоматического парсинга сайтов и другой ресурсоемкий вредоносный трафик.
Например, вместо тотальной блокировки всех автоматизированных запросов, можно настроить брандмауэр таким образом, чтобы жестко блокировать только «однозначно вредоносный автоматизированный трафик», при этом беспрепятственно пропуская «проверенных ботов», таких как краулеры поисковой системы Google, Bing или полезные сервисы мониторинга доступности сайта.
Что этот технологический сдвиг означает для сайтов на WordPress
ИИ-сканеры уже прочно вошли в экосистему интернета и стали неотъемлемой частью процесса поиска информации людьми. Данная технология пока находится на стадии активного формирования: юридические правила и технические стандарты продолжают дорабатываться, а владельцы сайтов по всему миру тестируют различные стратегии, определяя, какой объем своих знаний они готовы бесплатно предоставить нейросетям.
Безусловным плюсом является то, что проекты на платформе WordPress изначально находятся в крайне выгодном положении. Благодаря надежной архитектуре, генерирующей чистый, семантически правильный HTML-код, большинство ИИ-сканеров могут быстро и безошибочно анализировать контент без необходимости создания специальных XML-карт или дополнительных ухищрений со стороны программистов.
Главное стратегическое решение для бизнеса сегодня заключается не в технических возможностях закрыть сайт от ботов, а в поиске идеального баланса: как обеспечить нейросетям ровно тот уровень доступа, который будет способствовать росту узнаваемости бренда, не подвергая при этом риску кражи уникальные коммерческие материалы. Сочетание продуманных правил в robots.txt и мощной облачной защиты от нежелательного трафика позволяет выстроить надежный фундамент для успешного развития ресурса в новую эру искусственного интеллекта.
Соседние материалы | ||||

|
Тестирование расширений на доступность: как проверить соответствие WCAG | Как использовать PHPStan для тестирования расширений Joomla |

|
|

