JoomGrabber - Расширение Joomla
Мечтаете об уникальном инструменте, который мог бы захватывать / извлекать что-либо извне и сохранять это в любых сторонних расширениях Joomla? Или просто автоматическая публикация из RSS-канала в статьи с контентом? Или расширение агрегатора RSS Joomla?

Особенности расширения
Миссия JoomGrabber - осуществить эту мечту. Этот компонент Joomla для захвата может собирать любые внешние источники данных (RSS, XML, NewsML, Youtube, ebay, электронная почта) и сохранять их в любом стороннем расширении Joomla (K2, FLEXIcontent, DocMan , VirtueMart). Этот автоматизированный движок агрегатора Joomla предлагает вам полный контроль над:
- Где собирать контент для вашего сайта Joomla
- Как переформатировать контент, прежде чем передавать его стороннему расширению Joomla.
- Где будет храниться контент.
- Сбор контента из любых внешних источников
- Переформатируйте собранный контент с помощью интеллектуальных процессоров
- Храните в любом стороннем Joomla! расширении
- Автоматический запуск с Cronjob (планировщик)
- Система журналов.
RSS Reader для чтения RSS-канала, предлагающего функцию RSS-канала для публикации. Links Finder - этот движок следует использовать для получения URL-адресов элементов с любых веб-страниц HTML. С легкостью покупайте продукты Ebay. Разберитесь с настроенным почтовым ящиком, чтобы получить содержимое электронной почты. TxtFolder - этот движок получает файлы .txt из настраиваемой папки и возвращает имя файла как заголовок, а текстовое содержимое - как полнотекстовый. XMLFolder - этот движок получает файлы .xml из настраиваемой папки и возвращает имя файла и теги xml в качестве выходных данных. Выбирает видео из любых плейлистов Youtube. Специальный движок, который может собирать новости из базы новостей Google по ключевым словам.
Спецификации:
| Дата выхода: | 19-11-2014 | |
| Дата обновления: | 19-12-2025 | |
| Тип расширения: | Платный | |
| Лицензия: | GPL | |
| Тематика: | Инструменты | |
| Совместимость: | J3.x J4.x J5.x J6.x | |
| Включает в себя: | Компонент Плагин | |
| Языковые пакеты: |
|
|
| Разработчик: | JoomBoost | |
| Рейтинг: | ||
Скачивание по подписке!
Вам необходимо авторизоваться на сайте и приобрести клубную подписку!
Поделись с друзьями!
Руководство по настройке JoomGrabber для автоматической публикации контента в Joomla
JoomGrabber полезен не тогда, когда нужно просто "добавить RSS на страницу", а когда сайту Joomla требуется управляемый поток внешних данных: взять элементы из источника, очистить или дополнить поля, сопоставить их с материалами Joomla или сторонним компонентом и затем запускать процесс вручную или по расписанию. В этом руководстве разберём практическую сторону работы с расширением: как спланировать pipe, какие настройки проверить после установки, как собрать первый сценарий импорта, где чаще всего ломается полный текст и изображения, как тестировать результат до автоматического запуска.

Материал не заменяет официальную документацию и не обещает универсальный импорт с любого сайта. У агрегаторов контента всегда есть границы: разные RSS-ленты отдают разный набор полей, некоторые сайты не позволяют корректно забрать полный текст, изображения могут быть защищены или отдаваться через относительные ссылки, а автоматическая публикация требует аккуратной проверки авторских прав и качества. Поэтому ниже акцент сделан на безопасной схеме работы, а не на "включить всё и забыть".
Руководство рассчитано на администратора Joomla, который уже умеет устанавливать расширения, создавать категории и проверять материалы в админ-панели. Если вы только оцениваете продукт перед установкой, начните с разделов о назначении, требованиях и похожих решениях. Если расширение уже установлено, переходите к блокам про pipe, настройки, практический пример и диагностику.
Где JoomGrabber действительно помогает, а где лучше не торопиться
JoomGrabber относится к классу расширений для сбора и преобразования данных. Его сильная сторона - не красивый вывод RSS-ленты на странице, а автоматизация цепочки "источник -> подготовка -> публикация". Официальные источники описывают несколько типов источников: RSS, XML, NewsML, YouTube, eBay, email, локальные TXT/XML-папки, Google News и ссылки, найденные на HTML-страницах. На стороне Joomla результат можно сохранять не только в стандартные материалы, но и в K2, VirtueMart, ZOO, Kunena, Docman, FlexiContent, EasyBlog и другие поддерживаемые адаптеры.
Практически это значит, что расширение подходит для сайтов с повторяемым контентным процессом. Например, отраслевой портал может собирать новости из нескольких разрешённых RSS-источников, редакция может создавать черновики материалов для последующей ручной проверки, каталог может подтягивать структурированные данные из XML, а видеосайт может импортировать метаданные роликов из YouTube-плейлиста. В каждом случае ценность появляется только тогда, когда входные данные стабильны и заранее понятно, куда попадёт каждое поле.
Не стоит воспринимать JoomGrabber как инструмент для бездумного копирования чужих публикаций. Технически расширение умеет забирать данные, но ответственность за право использования источника, наличие ссылки на оригинал, качество текста, отсутствие дублей и соответствие редакционной политике остаётся на владельце сайта. Если источник запрещает перепубликацию, отдаёт только короткий анонс или меняет разметку каждую неделю, автоматизация может дать больше ручной чистки, чем пользы.
Кому расширение подойдёт
JoomGrabber логичен для администраторов, которым нужен контролируемый импорт в Joomla, а не внешний виджет. Особенно хорошо он раскрывается, когда у сайта есть несколько похожих источников, понятная структура категорий и редактор, который периодически проверяет результат. Отзывы в JED показывают типичные сценарии: RSS-новости для отраслевого сайта, биржевая информация, импорт в K2 и обработка данных перед публикацией.
- Новостные и отраслевые сайты, которые работают с разрешёнными RSS-лентами и хотят ускорить подготовку черновиков.
- Каталоги и магазины на Joomla, где часть данных приходит из XML, email или других структурированных источников.
- Сайты с K2, VirtueMart, ZOO, FlexiContent или EasyBlog, если нужен не просто импорт текста, а привязка к полям конкретного компонента.
- Администраторы, которым важно тестировать каждый шаг: выход движка, результат процессора, mapping в адаптере и финальную запись в базе Joomla.
Когда лучше выбрать другой путь
Если задача ограничивается показом собственной RSS-ленты наружу, JoomGrabber может быть избыточен - здесь ближе JoomRSS или штатные возможности Joomla. Если нужен импорт только из социальных сетей в простую категорию, проще оценить JA Social Feed. Если вы не готовы проверять источники, права и качество публикаций, автоматический импорт лучше заменить ручной редактурой или полуавтоматическим процессом с черновиками.
Безопасная позиция для первого запуска: сначала публикуйте импортированные элементы в закрытую категорию или статус черновика, проверьте структуру, изображения, ссылки и дубли, и только после этого включайте автоматическую публикацию в рабочий раздел.
Что проверить перед установкой расширения
Перед установкой важно разделить две проверки: техническую готовность Joomla и готовность контентного процесса. Официальные системные требования указывают Joomla 4/5, PHP 8 или выше, включённые JSON, cURL, mbString, функции file_get_contents, simplexml_load_string, simplexml_load_file, dom_import_simplexml, а также классы SimpleXMLElement и ArrayObject. На странице продукта дополнительно указана совместимость с Joomla 3, 4, 5 и 6, но для нового проекта разумнее ориентироваться на актуальную ветку Joomla и требования документации.
Техническая проверка нужна не для формальности. JoomGrabber активно обращается к внешним URL, разбирает XML/HTML, сохраняет изображения, выполняет cron-запуски и иногда работает с большими текстами. Если на хостинге отключён cURL, запрещены внешние запросы, слишком мал лимит времени выполнения или закрыта запись в нужные директории, ошибки появятся не в момент установки, а во время первого реального pipe.
Минимальный чек перед установкой
- Сделайте резервную копию сайта и базы данных перед установкой расширения.
- Проверьте версию Joomla и PHP, а также наличие нужных PHP-расширений у хостинга.
- Убедитесь, что у администратора есть права на установку компонентов и настройку ACL.
- Подготовьте тестовую категорию Joomla или отдельную категорию K2, чтобы первый импорт не попал сразу в рабочую ленту.
- Выберите один легальный и стабильный источник для первого pipe, желательно RSS с понятными полями title, link, description и date.
- Проверьте, нужен ли вам сторонний адаптер: K2, VirtueMart, ZOO, Kunena, Docman, FlexiContent или EasyBlog.
Контентная готовность важнее числа источников
Ошибка многих первых запусков - добавлять сразу десять источников и десяток процессоров. Для JoomGrabber лучше идти от простого к сложному. Один источник, один адаптер, два-три процессора и ручной запуск дают больше понимания, чем большая автоматическая схема без диагностики. Когда базовый сценарий стабилен, можно копировать pipe, менять источник и постепенно добавлять фильтры, сохранение изображений, формат даты, ссылку на оригинал или более точный HTML Parser.
Если источник отдаёт только короткое описание, JoomGrabber не обязан волшебно получить полный текст. Документация прямо предупреждает, что Get Fulltext работает не со всеми сайтами. Это нормальное ограничение автоматического парсинга, а не обязательно ошибка настройки.
Как устроен pipe: движок, процессоры и адаптер
Ключевая идея JoomGrabber - pipe, то есть последовательная цепочка обработки. В официальном обзоре эта цепочка описана как Engine, Processors и Adapter. Движок получает исходные данные: RSSReader читает RSS, Links Finder собирает ссылки со страницы, Email берёт письма из почтового ящика, XMLFolder читает XML-файлы из папки, YouTube Engine получает данные роликов. Процессоры изменяют или дополняют поля: создают alias, берут полный текст по ссылке, выделяют картинки, фильтруют ключевые слова, удаляют теги, объединяют поля, заменяют текст через регулярные выражения. Адаптер принимает подготовленные поля и сохраняет результат в целевой компонент Joomla.

Такой подход удобен тем, что вы можете увидеть проблему на конкретном участке. Если RSSReader отдаёт title и link, но Get Fulltext возвращает пустой результат, значит источник или настройки извлечения требуют проверки. Если изображения есть в fulltext, но не попадают в intro image, смотрите Images processor и mapping адаптера. Если материал сохраняется не в ту категорию, проверяйте не движок, а адаптер и его поля.
Engine отвечает за исходные поля
Первый вопрос при настройке: какие поля реально отдаёт выбранный движок. У RSSReader обычно ожидаются дата, заголовок, ссылка и описание. Links Finder может вернуть title, link, title_attribute и alt_attribute. YouTube Engine в документации описан богаче: ссылка, идентификатор ролика, описание, дата публикации, изображения разных размеров, channel_title, channel_id и готовый embed-код. Чем богаче выход движка, тем меньше нужно выдумывать на стороне процессоров.
Processors превращают сырой поток в материал
Процессоры не стоит включать "на всякий случай". Каждый процессор должен иметь понятную задачу: Alias нужен для человекочитаемого URL, Duplicate - для защиты от повторов, Keywords Filter - чтобы не брать лишние элементы, Get Fulltext или Article Extractor - чтобы получить полный текст, Get Images/Save Image - чтобы обработать медиа, Original Source - чтобы сохранить ссылку на первоисточник, Combine - чтобы собрать поле из нескольких частей. Если процессор не связан с проблемой, он только усложняет диагностику.
Adapter фиксирует результат в Joomla
Адаптер - последний участок pipe. Именно здесь решается, где окажется материал: в стандартных статьях Joomla, K2, VirtueMart, ZOO, Kunena, Docman, FlexiContent или EasyBlog. Важный нюанс: один и тот же выход процессора может попадать в разные поля адаптера. Например, title идёт в заголовок, alias - в alias, description или fulltext - в текст, image field - в intro image, original link - в отдельное поле или в конец материала. В K2 custom fields дополнительно важны правила разделителей для разных типов поля, и официальная документация предлагает использовать Combine processor для некоторых полей.
Рабочее правило mapping: прежде чем запускать cron, сохраните pipe вручную, откройте один импортированный материал и проверьте каждое поле: заголовок, alias, категорию, автора, текст, изображение, ссылку на оригинал и статус публикации.
Установка и первая проверка в админ-панели Joomla
Установка JoomGrabber выполняется как обычная установка расширения Joomla. В зависимости от версии админ-панели путь может немного отличаться, но логика остаётся стандартной: загрузить ZIP-пакет через экран установки расширений, дождаться сообщения об успешной установке, затем открыть компонент через меню компонентов. JED и документация Joomla напоминают, что расширения устанавливаются пакетами, а компоненты затем появляются в меню администратора.
После установки не начинайте с cron и нескольких источников. Сначала проверьте, что компонент открывается, что доступна страница настроек, что пользователь видит нужные меню, а в списке pipe можно создать новый элемент. Если на сайте несколько администраторов, сразу настройте права через Joomla ACL: кому можно редактировать pipe, кому можно запускать публикацию, а кому достаточно просматривать результаты. JoomGrabber заявляет поддержку Joomla ACL, значит эту часть лучше использовать, а не отдавать всем полный доступ Super User.
Первичный порядок действий
- Установите ZIP-пакет расширения через стандартный экран установки Joomla.
- Откройте компонент JoomGrabber в админ-панели и убедитесь, что страницы загружаются без PHP-предупреждений.
- Откройте настройки компонента и проверьте общие параметры запуска, логирования и расписания.
- Создайте тестовую категорию в Joomla Content или целевом компоненте, если она ещё не подготовлена.
- Проверьте права ACL: кто может создавать, редактировать и запускать pipe.
- Создайте первый pipe только для одного источника и сохраните его до добавления сложных процессоров.
Что проверить после установки
В первую очередь проверьте доступность внешних запросов. Если хостинг блокирует исходящие HTTP-запросы или требует прокси на уровне сервера, RSSReader, Get Fulltext и YouTube Engine могут вести себя нестабильно. Затем проверьте запись файлов, если планируете сохранять изображения локально. После этого сделайте ручной запуск одного pipe через кнопку тестирования или публикации в списке pipe. Автоматизацию включайте только после того, как ручной запуск дал предсказуемый результат.
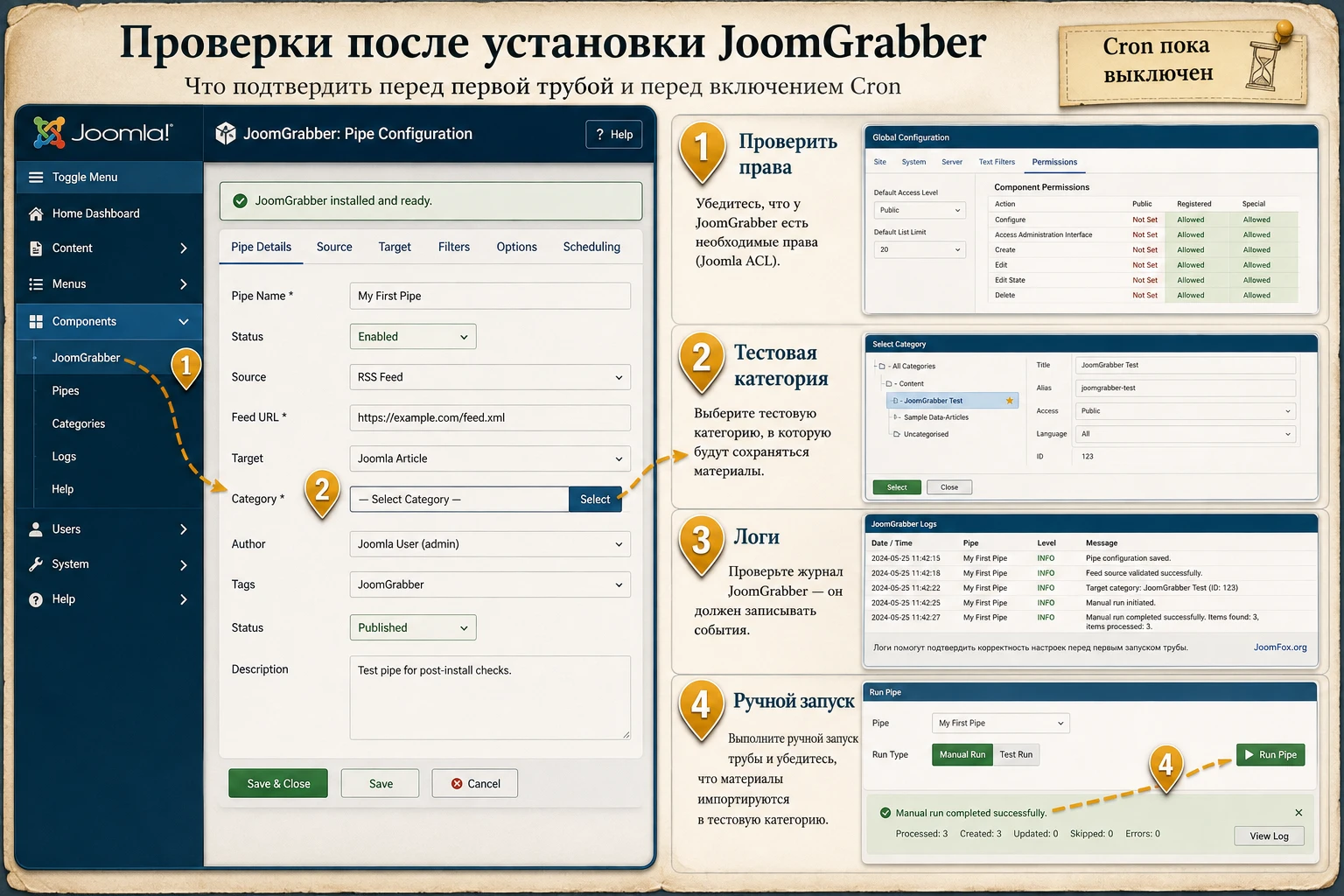
Лучшие настройки для первого рабочего pipe
Первый pipe должен быть учебным и полезным одновременно. Выберите источник, где вы точно понимаете структуру данных. Для RSS это обычно title, link, description и date. Для HTML-страницы с множеством ссылок сначала нужен Links Finder, затем Get Fulltext или Article Extractor. Для YouTube лучше заранее подготовить playlist ID, channel ID или поисковый запрос и ключ YouTube Data API v3, потому что документация указывает API key как обязательный параметр для YouTube Engine.
В типовом сценарии RSS в Joomla Content достаточно начать с RSSReader, Content Adapter, Duplicate, Alias, возможно Get Fulltext и Original Source. Images processor добавляйте только после того, как полный текст или исходное HTML-поле действительно содержит изображения. Keywords Filter лучше включать после первого просмотра данных, иначе можно случайно отфильтровать всё и ошибочно решить, что источник не работает.
Настройки источника и лимиты
Для первого запуска задайте небольшой лимит элементов. Если источник отдаёт много записей, не нужно импортировать весь архив. Возьмите 3-5 элементов, проверьте поля, затем постепенно увеличивайте лимит. У Links Finder используйте точный Container Area через XPath или CSS selector и Absolute Host, если ссылки относительные. У RSSReader смотрите, какие поля реально приходят из ленты. У YouTube Engine выбирайте source type осознанно: playlist для конкретного списка, channel для одного канала, search для поиска.
Дубли и alias
Защита от дублей - одна из базовых настроек для автоматической публикации. Duplicate processor в списке возможностей нужен именно для того, чтобы не создавать повторные элементы из одного источника. На практике проверяйте, по какому полю он сравнивает записи в вашем pipe. Если источник меняет title, но link стабилен, опора на ссылку может быть надёжнее. Alias processor нужен для URL, но не заменяет проверку дублей: красивый alias не гарантирует уникальность данных.
Фильтры ключевых слов
Keywords Filter processor поддерживает включающие и исключающие условия. В документации показаны примеры с обязательным словом через плюс и исключением через минус. Для редакционного сайта это удобно, когда нужно брать только материалы по теме и не забирать нерелевантные записи из широкой ленты. Начинайте с мягких правил и обязательно тестируйте, сколько элементов остаётся после фильтра. Слишком строгий фильтр легко создаёт пустой импорт.
Изображения и локальное сохранение
Images processor работает с HTML source или URL оригинального материала. Если вы хотите сохранить картинки на свой сервер, включайте локальное сохранение и задавайте директорию. Если оставляете удалённые изображения, правильно указывайте Origin URL, особенно когда источник использует относительные пути. Clear Tiny помогает убрать пиксельные трекеры, иконки и служебные изображения. Make list нужен, когда нужно передать список изображений в поле адаптера, например для intro image или K2 image tab.
Ссылка на оригинал и качество публикации
Для контентной этики и навигации часто полезно сохранять ссылку на первоисточник. В списке процессоров есть Original Source, а в документации есть отдельная тема про ссылку на автора или источник. Даже если вы публикуете только разрешённый фрагмент или анонс, пользователь должен понимать происхождение материала. Для редакции это также упрощает проверку: если импорт выглядит странно, можно быстро открыть исходную страницу и сравнить результат.
Практический пример: RSS-лента в материалы Joomla с ручной проверкой
Разберём сценарий, который подходит для первого реального теста: импортировать несколько записей из разрешённой RSS-ленты в тестовую категорию Joomla Content, сохранить заголовок, ссылку, описание, alias и при возможности изображение. Цель не в том, чтобы сразу построить идеальный агрегатор, а в том, чтобы пройти полный путь и увидеть, где JoomGrabber отдаёт данные, где они преобразуются и как выглядят в Joomla.
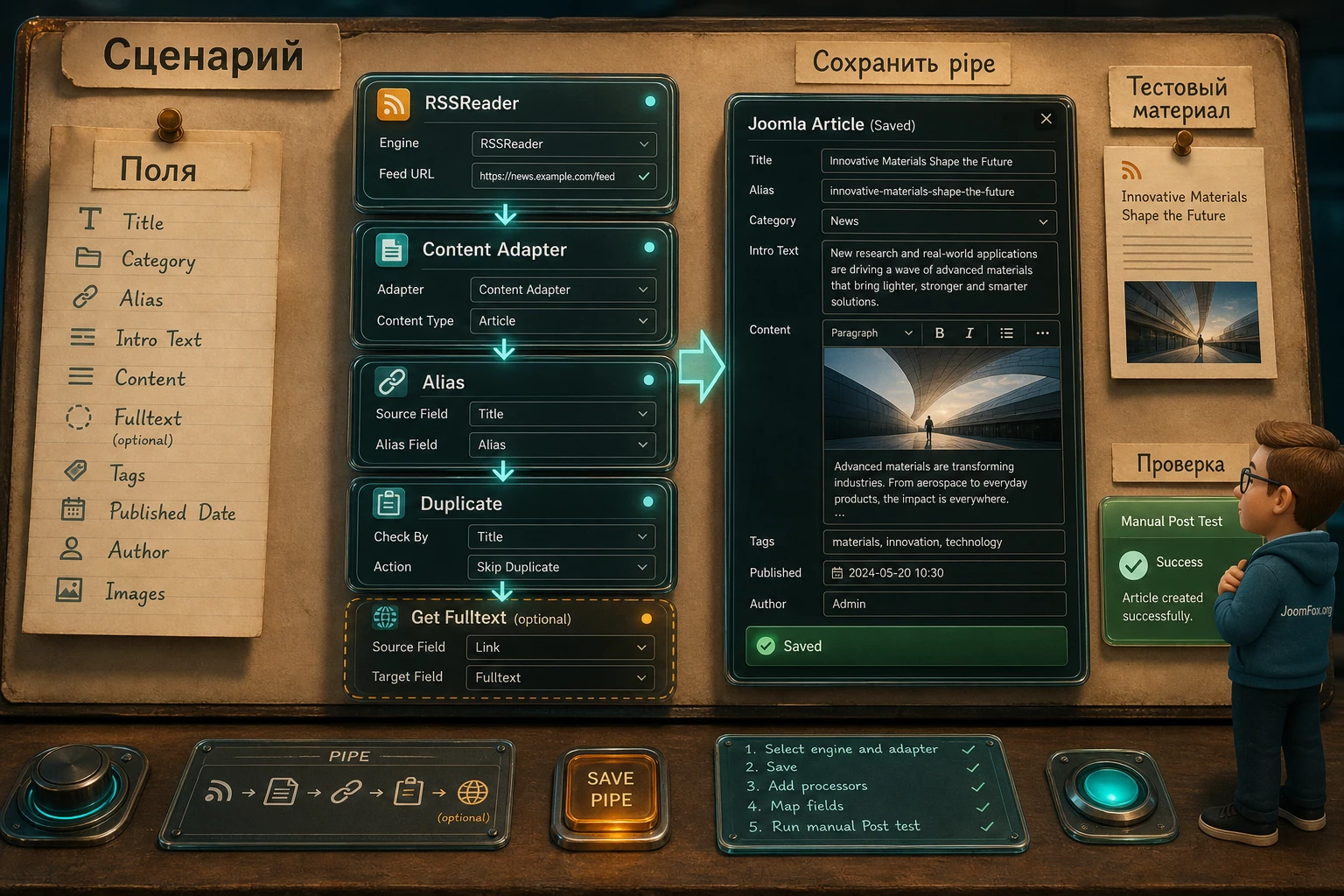
Цель
Получить 3-5 новых материалов в тестовой категории Joomla. Каждый материал должен иметь понятный заголовок, текст из RSS description или fulltext, корректный alias, ссылку на первоисточник и статус, который не навредит рабочему сайту. Если импорт изображений пока не стабилен, лучше оставить картинки на втором проходе, чем смешивать две проблемы в одном тесте.
Подготовка
Создайте категорию вроде "Импорт - проверка" и закройте её от публичного меню, если не хотите показывать тестовые материалы. Выберите RSS-ленту, где условия использования допускают импорт или цитирование. Проверьте ленту в браузере: должны быть видны элементы с title, link и description. Если лента пустая или требует авторизацию, сначала решите эту проблему вне JoomGrabber.
Шаги настройки
- В JoomGrabber создайте новый pipe и выберите RSSReader как Engine.
- Введите Feed URL и задайте небольшой лимит элементов, если параметр доступен в вашем экране настройки.
- Выберите Content Adapter и укажите тестовую категорию Joomla.
- Сохраните pipe до настройки процессоров, потому что официальная инструкция для K2-сценария подчёркивает порядок: сначала engine и adapter, затем сохранение и processors.
- Добавьте Alias processor для формирования alias из заголовка.
- Добавьте Duplicate processor, чтобы не создавать повторные элементы при повторном запуске.
- Если нужен полный текст, добавьте Get Fulltext processor и подайте в него link из RSSReader.
- Если в полном тексте есть изображения, добавьте Images processor и настройте локальное сохранение или корректный Origin URL.
- Сопоставьте output fields процессоров с input fields Content Adapter: title, alias, introtext/fulltext, category, image, source link.
- Сохраните pipe и запустите ручной тест через список pipe.
Проверка результата
После ручного запуска откройте список материалов Joomla. Проверьте количество созданных элементов, заголовки, alias, категорию, статус, автора, текст, наличие ссылок и изображений. Затем откройте один материал в публичной части сайта, если категория доступна, и сравните результат с исходным RSS. Важно смотреть не только на наличие текста, но и на качество HTML: нет ли лишних блоков, битых картинок, пустых абзацев, мусорных ссылок и повторов.
Нюанс, который часто экономит время
Если description импортируется нормально, а fulltext пустой, не ломайте весь pipe. Сначала отключите Get Fulltext и убедитесь, что базовый RSS-сценарий работает. Потом верните Get Fulltext, попробуйте другой cURL level, а если источник всё равно не отдаёт контент, переходите к HTML Parser или Article Extractor. Так вы отделите проблему источника от проблемы адаптера.
Мини-итог: первый успешный pipe - это не максимальный импорт, а воспроизводимая схема, где понятно, откуда берётся каждое поле и как проверить результат в Joomla.
Полный текст, HTML Parser и Article Extractor
Для многих сайтов RSS-лента отдаёт только анонс. Поэтому возникает желание "дотянуть" полный текст по ссылке. В JoomGrabber для этого есть Get Fulltext processor, HTML Parser и более новый Article Extractor. Но здесь важно понимать границы. Документация прямо говорит, что Get Fulltext не работает с каждым сайтом. Причины могут быть разными: нестандартная разметка, защита от автоматических запросов, JavaScript-загрузка, редиректы, неправильная кодировка, отсутствие полного текста в открытом HTML или ограничения самого источника.
Get Fulltext удобен как первый уровень. Он принимает ссылку или HTML text field и отдаёт fulltext и full_html. Параметры Clear Tags, clear Attribute, Clear Space и Auto Fulltext помогают очистить результат. Если автоматический режим не справляется, Parser Code позволяет вручную выделять фрагменты HTML. Это уже требует понимания структуры исходной страницы, поэтому настройку лучше делать на одном конкретном источнике, а не на всех сразу.
Когда использовать HTML Parser
HTML Parser подходит, когда вы видите нужный блок в исходном HTML и можете описать, как его выделить. В документации упоминаются команды вроде ginner, remove, split, wrap и replace. Это не визуальный конструктор, а язык маленьких операций над HTML. Используйте его, если Auto Fulltext забирает слишком много мусора или не находит основной блок, но исходная страница остаётся предсказуемой.
Когда смотреть на Article Extractor
Article Extractor описан как enhanced content extraction tool с PHP-Readability в качестве основного механизма, optional AI refinement, content spinning, HTML preservation и fallback. Такой процессор полезен, когда источники похожи на обычные статьи и нужно аккуратнее выделять основной текст. Но не нужно включать AI-обработку без необходимости. Если вам достаточно корректно взять description и ссылку, дополнительная перезапись текста только усложнит контроль качества и юридические вопросы.
Почему не стоит строить pipe вокруг одной хрупкой разметки
Если HTML Parser завязан на точный класс блока, а источник меняет шаблон, импорт может внезапно стать пустым или начать забирать боковую колонку. Поэтому для важных сайтов заводите отдельный pipe на каждый тип источника, сохраняйте тестовый пример и периодически проверяйте логи. Если один источник критичен для проекта, лучше предусмотреть ручную редакционную проверку, чем полностью доверять автоматическому парсеру.
Links Finder, XPath и работа с источниками без готовой RSS-ленты
Не каждый источник отдаёт удобную RSS-ленту. Иногда на сайте есть страница-рубрика с карточками материалов, ссылками на новости, документами или товарами, но RSS отсутствует или содержит только часть данных. Для таких случаев в JoomGrabber есть Links Finder Engine и отдельные процессоры, которые помогают сначала получить список URL, а затем вытянуть из каждой страницы нужный фрагмент. Это уже более сложный сценарий, чем RSS, потому что вы работаете не с готовым XML-потоком, а с HTML-разметкой конкретного сайта.
Документация Links Finder описывает Container URLs, Container Area Extraction Method, Container Area, Item Format, Limit, Decode, Format Page, Absolute Host, List Elements, Force Title и Get Title From Link. Практически это означает, что вы задаёте страницу-контейнер, указываете область или селектор, где находятся элементы, и получаете выходные поля title, link, title_attribute и alt_attribute. После этого link можно передать в Get Fulltext, Article Extractor, HTML Parser или XPath processor.
Когда Links Finder лучше RSS
Links Finder уместен, когда RSS не существует, отдаёт слишком короткий поток или не содержит нужных ссылок. Например, сайт публикует каталог документов, где каждая карточка ведёт на отдельную страницу с PDF, изображением и описанием. RSS может отсутствовать, но HTML-страница предсказуема: все карточки лежат в одном блоке, ссылки имеют похожий формат, заголовки читаются из атрибута или текста ссылки. В такой ситуации Links Finder создаёт первый слой pipe: не сам контент, а список задач для дальнейшей обработки.
Однако этот режим чувствителен к разметке. Если источник меняет классы, переносит ссылки в другой блок или добавляет рекламные элементы, селектор может начать возвращать лишнее. Поэтому для Links Finder особенно важны Limit и тестирование на маленькой выборке. Не ставьте сразу большой лимит и не запускайте cron, пока не убедитесь, что список ссылок действительно состоит из нужных элементов.
CSS selector или XPath
В документации Links Finder показаны оба подхода: XPath и CSS selector. Для администратора без опыта парсинга чаще проще CSS selector, потому что он похож на правила стилей. XPath точнее в сложных случаях, когда нужно обратиться к конкретной структуре DOM, но он требует аккуратности. XPath processor также может извлекать куски из HTML, который уже пришёл от другого процессора. Это полезно, если full_html содержит много лишнего, но нужное поле находится в стабильном элементе.
Не выбирайте самый общий селектор. Если взять все ссылки на странице, pipe может импортировать меню, хлебные крошки, рекламные ссылки и служебные элементы. Лучше выделить родительский блок списка и только внутри него искать ссылки материалов. Если источник имеет пагинацию, отдельно проверьте Format Page и не включайте обход страниц, пока первая страница не работает без лишнего мусора.
Проверка ссылочного pipe
Для ссылочного pipe проверка должна идти в два этапа. Сначала убедитесь, что Links Finder возвращает правильные URL и заголовки. На этом этапе не нужен Get Fulltext и не нужен адаптер публикации. Затем добавьте извлечение текста с одного-двух URL. Только после этого подключайте адаптер Joomla и сопоставление полей. Такой порядок позволяет не путать проблему поиска ссылок с проблемой извлечения текста или сохранения материалов.
Практическая подсказка: если источник не имеет RSS, но страница списка стабильна, Links Finder может быть сильнее RSS-сценария. Если разметка хаотична, скрыта JavaScript или часто меняется, лучше искать официальный feed, API, XML-файл или отказаться от автоматического импорта.
Адаптеры Joomla, K2, VirtueMart и поля сторонних компонентов
Одна из причин, почему JoomGrabber сложнее обычного RSS-модуля, - поддержка разных адаптеров. Стандартные материалы Joomla, K2, VirtueMart, ZOO, Kunena, Docman, FlexiContent и EasyBlog имеют разные модели данных. Заголовок и текст есть почти везде, но категории, изображения, custom fields, товарные поля, форумные темы, документы и блоговые метаданные устроены по-разному. Поэтому адаптер нельзя настраивать механически: нужно понимать, какие input fields он ожидает и какие output fields вы реально получаете от движка и процессоров.
Для Joomla Content обычно достаточно заголовка, alias, текста, категории, автора, статуса, изображений и при необходимости custom fields. Для K2 появляются свои категории, image tab и extra fields. Официальная документация по K2 custom fields показывает, что для некоторых типов поля нужно использовать Combine processor и разделители, например для link field или multiple select. Для VirtueMart сценарий ещё строже: товарные данные должны быть структурированы, а не просто помещены в fulltext.
Как не ошибиться при сопоставлении полей
Перед сопоставлением выпишите таблицу на бумаге или в заметках: "поле источника", "процессор", "выходное поле", "поле адаптера", "как проверить". Например, RSS title идёт в заголовок, Alias processor создаёт alias, RSS link идёт в Original Source, Get Fulltext fulltext идёт в full text, Images processor images[1] идёт в intro image. Такая схема кажется простой, но она помогает быстро увидеть пустые места: если image field пустой, не нужно менять категорию; если alias неверный, не нужно трогать RSS URL.
Если адаптер поддерживает custom fields, не начинайте с них. Сначала сохраните базовый материал. Потом добавьте одно custom field и проверьте. Затем второе. Если подключить сразу пять дополнительных полей, ошибку разделителя или типа поля будет сложнее найти. Для K2 link field и multiple select особенно важен формат, потому что значение должно соответствовать ожиданиям адаптера, а не просто выглядеть читаемо в тексте.
Категории, языки и уровни доступа
У Joomla-сайтов часто есть языки, уровни доступа и несколько редакционных зон. JoomGrabber поддерживает Joomla ACL, а Content Adapter в changelog упоминает работу с access level. Это значит, что права и доступность материалов нужно проверять так же внимательно, как текст. Если pipe сохраняет материалы в публичную категорию с неправильным языком или уровнем доступа, посетители могут увидеть тестовый импорт раньше редактора. Для многоязычного сайта заведите отдельные pipe на разные языковые источники и не смешивайте их в одной категории.
Черновики как нормальная часть процесса
Для ответственного сайта полезно использовать JoomGrabber не как мгновенный автопубликатор, а как генератор черновиков. Pipe собирает материалы, заполняет поля, сохраняет ссылку на источник и изображения, а редактор затем проверяет несколько последних записей. Такой режим особенно хорош для источников, где полный текст извлекается нестабильно или где каждую публикацию нужно адаптировать под стиль сайта. Автоматизация тогда снимает рутину, но не отменяет контроль.
Если после нескольких недель проверки источник стабилен, можно перевести часть pipe в опубликованный статус или включить более частый cron. Но даже тогда оставьте мониторинг логов и периодический просмотр свежих материалов. Любой внешний источник может изменить формат, и хороший pipeline должен быть не только мощным, но и наблюдаемым.
Изображения, медиа и сохранение источника
Картинки в импортированном контенте часто создают больше проблем, чем текст. Источник может отдавать относительные URL, lazy loading, srcset, WebP, маленькие иконки, изображения из CDN, запрещать hotlinking или вообще не включать изображения в RSS. JoomGrabber имеет Images processor, Save Image processor, Get Images и настройки вроде Clear Tiny, Make list, Number images, Origin URL и Get to local. Но эти настройки работают только тогда, когда входные данные действительно содержат изображения или корректную ссылку на страницу, где их можно найти.
Для первого прохода полезно разделить задачу на две: сначала импортировать текст и ссылку, потом подключить изображения. Если текстовый pipe уже стабилен, проще понять, что именно ломает медиа. Если изображения не появляются, проверьте input процессора: туда должен приходить HTML source с тегами img или URL оригинальной страницы. Затем проверьте Origin URL для относительных ссылок и директорию сохранения, если включено локальное хранение.
Как выбрать режим сохранения
Локальное сохранение даёт больше контроля: изображения остаются на вашем сервере, не зависят от hotlinking и лучше управляются резервными копиями. Но оно требует места, прав на запись и внимательной проверки прав использования. Удалённые изображения проще на старте, но могут исчезнуть, замедлить страницу или не открыться у посетителей. Для публичного сайта обычно разумнее локально сохранять только те изображения, которые вы имеете право использовать, и заранее ограничивать размер и количество.
Как не забирать лишнее
Clear Tiny помогает отсеять маленькие служебные картинки. Number images ограничивает количество. Remove может убрать img tags из html output, если нужно сохранить изображение отдельно, а не дублировать его внутри текста. Если источник часто вставляет рекламные блоки, лучше очистить HTML до Images processor или использовать HTML Parser, чтобы выделить только основной контентный блок.
Ссылка на оригинал как часть качества
В сценариях агрегации ссылка на источник полезна не только юридически, но и технически. Редактор может быстро открыть оригинал, проверить, почему картинка не загрузилась, сравнить заголовок, увидеть дату обновления и понять, не изменился ли формат источника. Поэтому даже если публично ссылка выводится не всегда, имеет смысл сохранять её в отдельное поле, custom field или служебную часть материала.
Cron, расписание и безопасный автоматический запуск
Автоматический запуск - одна из главных причин использовать JoomGrabber, но включать его нужно после ручной проверки. Официальная страница продукта перечисляет manual, autorun и cronjob modes, а документация по cron показывает варианты серверного запуска через wget, URL с secret key и CLI. Для владельца сайта важна не команда сама по себе, а режим эксплуатации: как часто запускать pipe, сколько элементов брать за раз, что делать при ошибке и где смотреть логи.
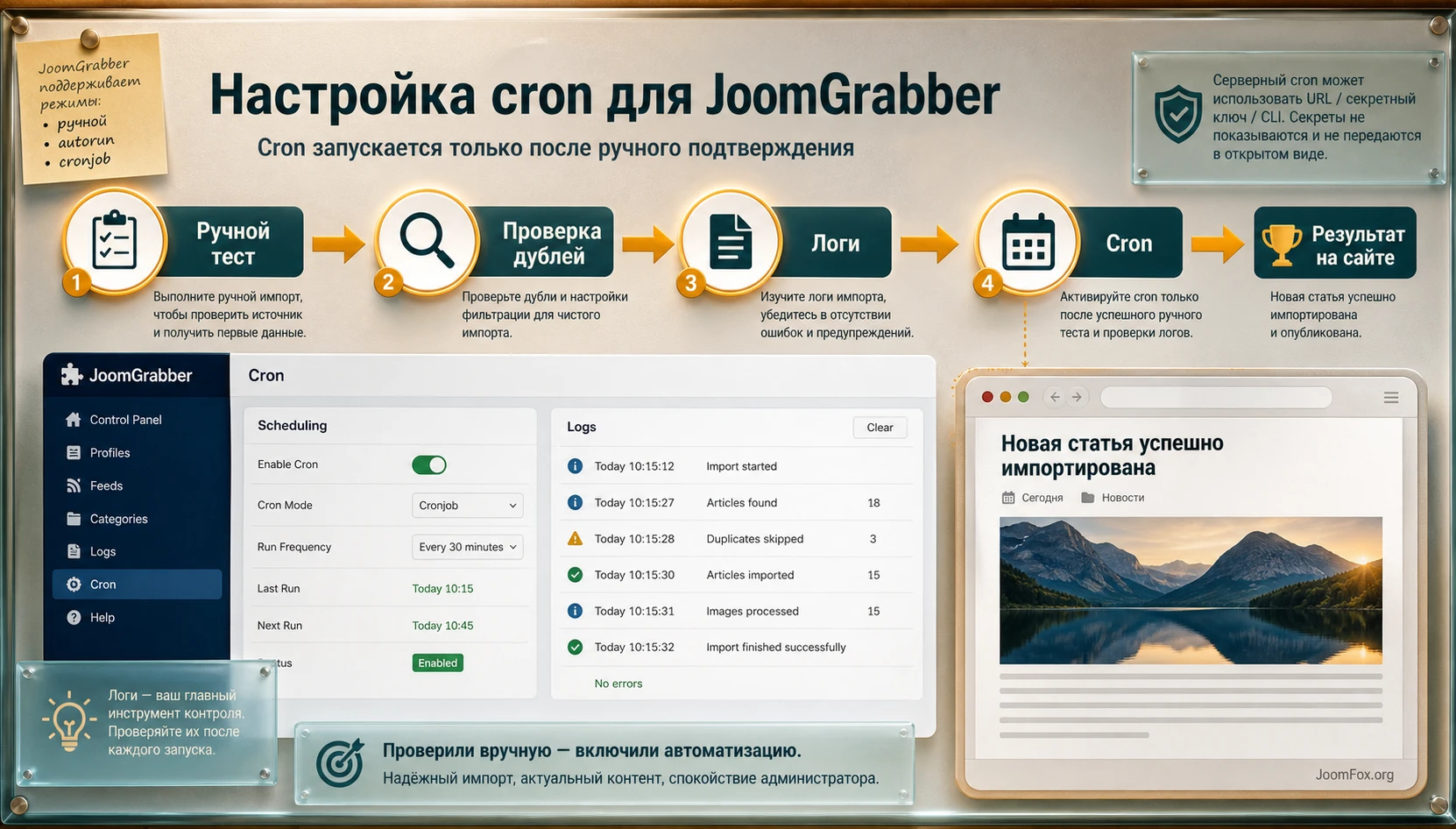
Как выбрать интервал
Не ставьте слишком частый запуск только потому, что cron это позволяет. Если источник обновляется раз в час, запуск каждые пять минут создаёт лишние запросы, нагрузку и шум в логах. Для новостной ленты можно начать с умеренного интервала, посмотреть, сколько новых элементов приходит, и скорректировать. Если pipe тяжёлый, берёт fulltext и изображения, интервал должен учитывать время обработки, лимиты хостинга и реакцию источника.
Почему нужен secret key или CLI
URL-запуск удобен, но его нужно защищать. Документация показывает вариант с secret key, а также CLI-команду. Не публикуйте реальный ключ в открытых материалах, логах и тикетах. Если есть возможность использовать CLI на хостинге, это часто стабильнее для тяжёлых задач, потому что запрос не зависит от браузера и некоторых веб-ограничений. Но конкретный путь к PHP и Joomla CLI нужно брать у хостинга.
Логи и ручной стоп
У JoomGrabber заявлена система логов, и её стоит включить на этапе настройки. Логи нужны, чтобы понимать, pipe ничего не нашёл, источник недоступен, процессор вернул пустой результат или адаптер не смог сохранить материал. Также заранее продумайте ручной стоп: если источник начал отдавать мусор, автоматическая публикация должна быть быстро отключена без удаления уже созданного output и без разрушительных действий в базе.
Перед cron-запуском проверьте три вещи: ручной импорт создаёт правильные материалы, дубли не плодятся при повторном запуске, а ошибки видны в логах и не проходят незамеченными.
Контроль качества импортированных материалов
Автоматическая публикация может быстро испортить сайт, если не контролировать качество. JoomGrabber даёт инструменты обработки, но не заменяет редакционные правила. Нужно заранее решить, что считать годным материалом: минимальная длина, наличие заголовка, обязательная ссылка на источник, отсутствие пустых изображений, корректная категория, нормальный alias, отсутствие дублей и нежелательных тем.
В JoomGrabber за это отвечают разные участки pipe. Keywords Filter отсеивает нерелевантные элементы, Duplicate предотвращает повторную публикацию, Alias формирует URL, Strip Tags чистит HTML, Regex Replacer может убрать повторяющийся мусор, Original Source сохраняет ссылку, Cut Introtext отделяет вступление от полного текста, Change Time корректирует дату, Combine собирает сложные поля. Но каждый инструмент нужно проверять на конкретном источнике.
Редакционный минимум для автоматической ленты
- Импортировать только из источников, где у вас есть право на публикацию, цитирование или агрегацию.
- Сохранять ссылку на оригинал, особенно если материал является анонсом или пересказом.
- Публиковать первые тесты в закрытую категорию или с непубличным статусом.
- Проверять дубли повторным ручным запуском одного и того же pipe.
- Ограничивать количество элементов за запуск, чтобы ошибка не создала сотни материалов.
- Следить за изображениями: не забирать логотипы, пиксели, рекламные баннеры и чужие медиа без права использования.
Когда включать AI-процессоры
В последних документах и changelog у JoomGrabber появились AI Presets, Text Spinner и Article Extractor с optional AI refinement. Это может помочь с очисткой и переработкой текста, но не должно становиться способом скрыть неразрешённое копирование. Для качественного сайта лучше использовать AI-обработку как вспомогательный этап для легально полученного контента или внутренних заготовок, а не как автоматическую маскировку чужого материала. Если вы подключаете такие процессоры, сначала тестируйте их на черновиках и сохраняйте HTML structure preservation только там, где это действительно нужно.
Проверка результата на сайте и в админ-панели
Проверка результата должна идти в двух плоскостях: данные в админ-панели и внешний вид в публичной части сайта. В админ-панели важно увидеть, что материал создан в правильном компоненте, категории и статусе. В публичной части - что тема Joomla корректно выводит текст, изображения, ссылку на источник, дату, автора и метаданные. Не ограничивайтесь сообщением "Pipe completed". Успешный технический запуск ещё не означает, что материал полезен посетителю.
Что смотреть в списке материалов
Проверьте заголовок, категорию, автора, состояние публикации, язык, уровень доступа, дату, alias, теги и custom fields. Если адаптер сохраняет данные в K2, VirtueMart, ZOO или другой компонент, проверьте специфичные поля этого компонента. В K2 это могут быть extra fields, image tab и category. В VirtueMart - поля товара, изображения и категории магазина. В Kunena - тема, текст и пользователь.
Что смотреть на публичной странице
Откройте материал как обычный посетитель. Проверьте, нет ли битого HTML, пустых блоков, гигантских изображений, двойных заголовков, странной кодировки или неработающих ссылок. Затем откройте исходную ссылку и сравните смысл. Если вы импортируете только анонс, он должен выглядеть как анонс, а не как оборванная статья. Если используете полный текст, убедитесь, что в нём нет навигации, cookie-блоков, рекламы и чужих виджетов.
Что делать после успешного теста
Когда один pipe стабилен, сохраните его как шаблон, если используете эту возможность. Затем создавайте похожие pipe по одному, а не массово. Для каждого нового источника повторяйте короткую проверку: fields output, processors output, adapter mapping, материал в админ-панели, публичная страница, повторный запуск на дубли, лог ошибок. Такой процесс кажется медленнее, но он защищает сайт от лавины некачественного импорта.
Частые проблемы JoomGrabber и понятная диагностика
Большинство проблем в JoomGrabber проще решать, если не менять сразу всё. Сначала определите участок: источник, движок, процессор, адаптер, cron, права или публичный вывод. Затем сделайте минимальный повтор на одном элементе. Ниже - типовые симптомы, причины и действия, характерные именно для расширений импорта контента в Joomla.

Pipe не создаёт материалы
Симптом: ручной запуск проходит, но новых материалов в Joomla нет. Возможные причины: источник не вернул элементов, фильтр ключевых слов отсёк всё, Duplicate processor считает элементы уже существующими, адаптер сохраняет в другую категорию, у пользователя нет прав или pipe остановился на ошибке процессора.
Проверьте выход Engine до процессоров. Если там пусто, проблема в source URL, лимите, доступе к внешним запросам или настройках движка. Если Engine отдаёт элементы, временно отключите фильтры и сложные процессоры. Затем проверьте adapter mapping и категорию. Откатывать стоит те настройки, которые были добавлены последними: Keywords Filter, Get Fulltext, Images или Regex Replacer.
Не получается забрать полный текст
Симптом: title и description импортируются, а fulltext пустой или содержит мусор. Документация JoomBoost прямо указывает, что Get Fulltext работает не со всеми сайтами. Сначала попробуйте сменить Get cURL с Level 1 на Level 2, если такой параметр доступен. Затем проверьте, есть ли полный текст в обычном HTML исходной страницы. Если текст загружается только через JavaScript или скрыт от внешних запросов, процессор может не справиться.
Исправление: используйте description как безопасный анонс, настройте HTML Parser под конкретную разметку или протестируйте Article Extractor. Если даже HTML Parser не помогает, лучше не строить автоматический импорт с этого источника. Для критичного источника может потребоваться отдельный custom processor, что уже выходит за рамки обычной настройки.
Images processor не возвращает картинки
Симптом: материал создан, но intro image или full image пустые. Проверьте input Images processor: туда должен попадать HTML с изображениями или URL оригинального материала. Если Get Fulltext вернул текст без img tags, Images processor нечего извлекать. Если изображения относительные, проверьте Origin URL. Если включено локальное сохранение, проверьте директорию и права записи.
Исправление: сначала добейтесь, чтобы full_html или выбранный HTML-блок содержал нужные изображения. Затем настройте Clear Tiny, Number images и Make list. Если источник запрещает hotlinking или отдаёт изображения через защищённые URL, не пытайтесь обходить ограничения - лучше отключить импорт картинок или получать медиа из разрешённого источника.
Материалы дублируются после cron
Симптом: при каждом запуске появляются новые копии одних и тех же записей. Возможные причины: Duplicate processor не включён, сравнение идёт по нестабильному полю, alias меняется, источник меняет параметры ссылок, а лимит снова берёт старые элементы.
Исправление: включите Duplicate processor ближе к началу обработки, выберите стабильное поле для сравнения, нормализуйте link или alias, уменьшите лимит и сделайте два ручных запуска подряд. Если после второго запуска новых элементов нет, можно возвращаться к cron.
Content Error при импорте
Симптом: ошибка появляется при импорте в Content, K2, ZOO или другой адаптер после Get Fulltext. Официальная заметка JoomBoost советует сначала изменить параметр Get cURL у Get Fulltext с Level 1 на Level 2 и протестировать снова. Если не помогло, вероятно, процессор не работает с выбранным источником.
Исправление: изолируйте Get Fulltext, попробуйте другой источник для сравнения, затем переходите к HTML Parser. Если ошибка возникает только на одном сайте, не меняйте глобальную логику всех pipe. Сделайте отдельный pipe или откажитесь от полного текста для этого источника.
Cron запускается, но результат непредсказуем
Симптом: вручную всё работает, а по расписанию часть элементов пропадает или pipe выполняется слишком долго. Возможные причины: слишком частый cron, маленький лимит времени на хостинге, тяжёлый Get Fulltext, сохранение многих изображений, внешние источники отвечают медленно, команда cron использует неправильный путь или URL без нужного ключа.
Исправление: уменьшите число элементов за запуск, увеличьте интервал, проверьте логи и протестируйте CLI-режим, если он доступен. Не запускайте несколько тяжёлых pipe одновременно. Если сайт начинает тормозить, временно отключите cron и вернитесь к ручному запуску до выяснения причины.
Ограничения, права и аккуратная работа с чужими источниками
Техническая возможность импорта не означает разрешение на публикацию. Это особенно важно для JoomGrabber, потому что расширение умеет работать с RSS, HTML-страницами, YouTube, email и другими источниками. Перед автоматизацией проверьте условия источника: разрешена ли перепубликация, нужен ли canonical или ссылка, можно ли сохранять изображения, допустим ли полный текст или только анонс. Если источник принадлежит вашей компании или партнёру, зафиксируйте правила в редакционном процессе.
Отдельный вопрос - качество и SEO. Массовая публикация одинаковых анонсов из RSS редко приносит пользу сама по себе. Сайт выигрывает, когда импорт используется как основа для справочника, мониторинга, внутренней базы или редакционного черновика, а не как поток случайных копий. Для публичных материалов добавляйте контекст, проверку фактов, уникальное вступление, аккуратные ссылки и структуру категорий.
Безопасный режим для рабочих сайтов
- Импортируйте первые элементы в непубличную категорию или черновики.
- Ограничивайте количество элементов за запуск, особенно при новом источнике.
- Сохраняйте ссылку на оригинал и проверяйте права на изображения.
- Не включайте полную автоматическую публикацию для источников, которые часто меняют разметку.
- Периодически просматривайте логи и выборку последних материалов.
Вопросы и ответы по JoomGrabber
Можно ли использовать JoomGrabber только для RSS в материалы Joomla?
Да, это один из самых понятных первых сценариев. Возьмите RSSReader как Engine, Content Adapter как цель, добавьте Alias и Duplicate, затем проверьте несколько элементов вручную. Полный текст, изображения и сложные фильтры добавляйте после базовой проверки.
Почему Get Fulltext не получает полный текст со всех сайтов?
Потому что сайты отдают контент по-разному. Часть страниц имеет предсказуемый HTML, часть использует JavaScript, защиту, редиректы или нестандартную структуру. Документация JoomBoost прямо указывает, что Get Fulltext не работает с каждым источником. Используйте cURL level, HTML Parser или Article Extractor, но не считайте сбой гарантированной ошибкой расширения.
Нужно ли сразу включать cron?
Нет. Сначала ручной запуск, затем повторный ручной запуск для проверки дублей, затем просмотр логов и только потом cron. Автоматический запуск ускоряет стабильный процесс, но также быстро размножает ошибки, если pipe ещё не отлажен.
Можно ли импортировать в K2 или VirtueMart?
Официальные источники указывают адаптеры для K2, VirtueMart, ZOO, Kunena, Docman, FlexiContent и EasyBlog. Но каждый компонент требует правильного mapping. Для K2 custom fields документация отдельно объясняет, как использовать Combine processor и разделители для некоторых типов поля.
Что делать, если изображения не сохраняются?
Сначала проверьте, есть ли изображения во входном HTML или на странице источника. Затем проверьте Origin URL, локальную директорию, Clear Tiny, Make list и Number images. Если источник блокирует загрузку или вы не имеете права использовать изображения, отключите импорт медиа и оставьте ссылку на оригинал.
Стоит ли включать AI Text Spinner для всех импортов?
Нет. AI-процессоры полезны только там, где они решают конкретную задачу и где вы контролируете право использования исходного текста. Для публичной редакционной ленты лучше сначала настроить корректный импорт, дубли, источники и ручную проверку. Перезапись текста не заменяет законность и качество.
Можно ли использовать JoomGrabber без сторонних компонентов?
Да, можно сохранять данные в стандартные материалы Joomla. Сторонние адаптеры нужны, если результат должен попадать в K2, VirtueMart, ZOO или другой компонент со своей структурой полей.
Когда JoomGrabber будет удачным выбором
JoomGrabber стоит тестировать, если вам нужен не виджет RSS, а управляемый импорт внешних данных в Joomla: с источником, фильтрами, обработкой HTML, изображениями, adapter mapping, логами и расписанием. Его особенно удобно рассматривать для сайтов, где контент приходит регулярно и имеет повторяемую структуру. Но сила расширения раскрывается только при дисциплине: один источник за раз, ручной тест, проверка дублей, аккуратные изображения, ясные права на публикацию и логи.
Если после чтения вы понимаете, какой источник будете использовать, в какую категорию сохранять результат и как проверить первый pipe, можно переходить к практическому тесту и скачать ZIP-архив. Начните с простого RSS-сценария, не включайте cron до ручной проверки и храните первый рабочий pipe как эталон для следующих источников.
Если же задача сводится к выводу собственной RSS-ленты, импорту социальных профилей без сложной обработки или разовой ручной публикации, сначала сравните альтернативы. Хороший выбор здесь не тот, где больше функций, а тот, где меньше лишней сложности для вашей реальной задачи.
Похожие расширения




Соседние материалы | ||||

|
DJ-Classifieds integrator - Расширение Joomla | Domus Organizer - Расширение Joomla |

|
|

